


Het zijn buzzwords in de serverwereld: hyper-converged servers en hyper-converged infrastructure (HCI). In feite gaat het om servers met eigen opslag in de vorm van ssd’s en harde schijven – dus geen centrale opslag. Maar het betekent zoveel meer…
Lees verder na de advertentie
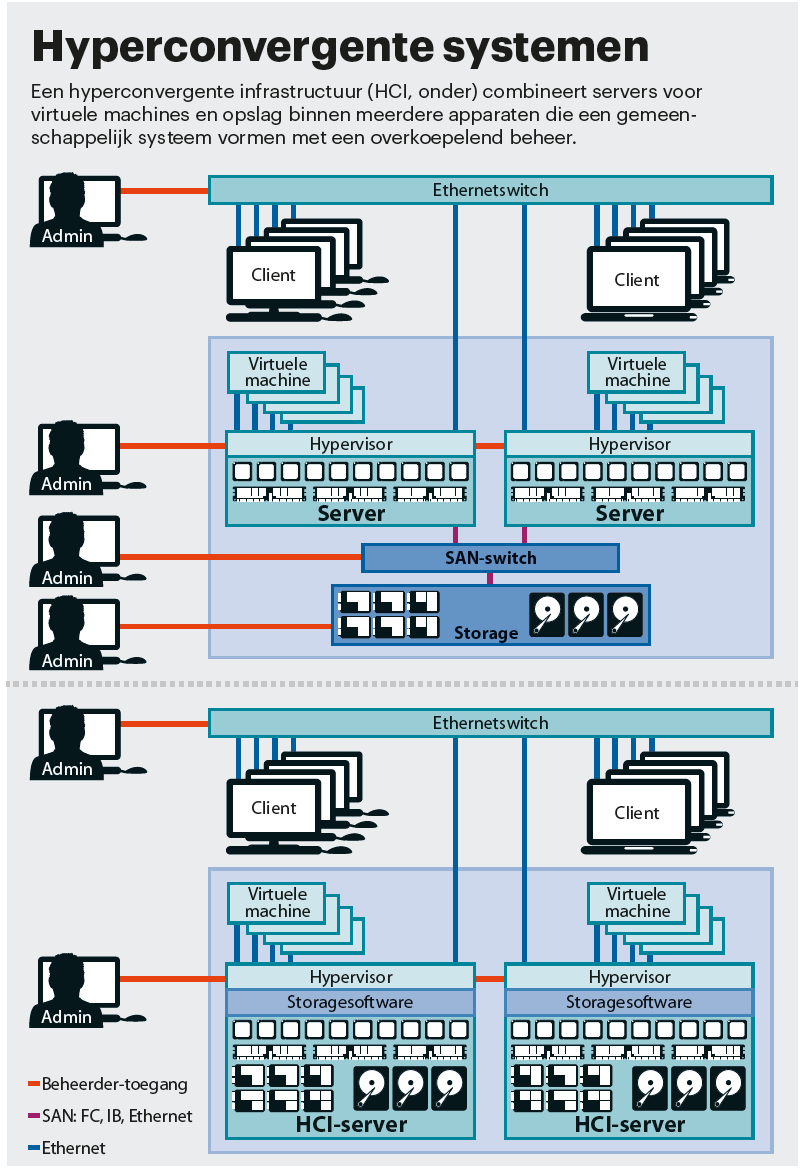
Veel IT-veteranen zullen wellicht een beetje moeten lachen als het woord hyper-convergence valt. Simpel gezegd gaat het hierbij om servers met ingebouwde harde schijven en ssd’s. De gegevens worden dus niet op een centraal opslagsysteem opgeslagen, maar op de servers zelf. Het concept achter hyper-converged infrastructure (HCI) behelst beduidend meer. Het omvat de inzet van talloze virtuele machines waarbij hardwarebronnen efficiënt worden gebruikt. Verder heeft het dankzij verregaande mate van automatisering een eenvoudig beheer en een hoge mate van integratie. Ook is het systeem eenvoudig uit te breiden. HCI-machines maken in de servermarkt de grootste groei door. Marktonderzoekers beweren zelfs dat het de reden is dat er minder andere opslagsystemen worden verkocht.
HCI wordt met name veel als platform voor virtuele desktops gebruikt. Grote bedrijven zetten die met miljoenen tegelijk in. Daarnaast wordt HCI steeds vaker voor algemene servertoepassingen als webhosting gebruikt. Achter HCI gaat een groot aantal concepten en functies schuil. Centraal daarbij is dat HCI in elke machine rekenkracht combineert met massaopslag. Daarbij kan het ook de opslag van meerdere machines tot een uniform systeem verenigen. Omdat je alles vanuit een beheerinterface kunt regelen, worden de prestaties hoger en het beheer en de automatisering eenvoudiger. Het zorgt ook voor een betere redundantie. Om HCI nog beter te begrijpen, richten we ons eerst op moderne virtualisatiemethoden en de gebruikelijke opslag-bottlenecks.
Virtualisatie
Tip!

Slimme IP-camera’s met live toezicht en haarscherpe beveiliging!

Het gebruik van virtuele machines (VM) is enorm toegenomen. Commerciële VM’s draaien meestal op 64-bit x86 machines met zogenaamde hypervisors. Hierbij moet je denken aan grote namen als VMware ESXi (vSphere), Microsoft Hyper-V, Citrix Xen-Server of Linux KVM. Bij gebruik van hypervisors valt vaak de term bare metal virtualization. Hierbij wordt geen volledig besturingssysteem geboot met daarop de virtualisatiesoftware. In plaats daarvan start een kaal systeem dat tot het broodnodige is gereduceerd. Het beschikt alleen over de vereiste drivers en functies voor remote management, waarop vervolgens de virtuele machines draaien.
Momenteel is weliswaar veel te doen om concurrerende concepten als Docker-containers. Maar die worden vooral ingezet bij nieuwe projecten van innovatieve webserviceproviders, wiens wereld zich veelal in de cloud afspeelt. De klassieke servervirtualisatie met hypervisors is daarentegen inmiddels standaard in zakelijke IT-omgevingen. Het dient voor het beschikbaar stellen van diensten en software die het hele bedrijf gebruikt. Denk daarbij aan Microsoft Exchange, databases maar ook aan virtuele desktops.
Automatisch
Het efficiënter inzetten van de beschikbare serverhardware is inmiddels van ondergeschikt belang. Belangrijker zijn de uitgebreide automatiseringsmogelijkheden. Een beheerder hoeft zich hiermee nauwelijks meer te bekommeren om compatibele drivers en specifieke hardware, want hij is vooral actief op de lagen boven de hypervisor. Welke producent de server ook heeft geleverd, de beheerder treft over het algemeen dezelfde functionaliteit aan. Een nieuwe virtuele server is hierdoor binnen een paar minuten klaar voor gebruik. Het enige wat de beheerder hoeft te doen is een vergelijkbare machine te klonen. Daarnaast kunnen allerlei routineklussen worden geautomatiseerd. Dit varieert van het maken van profielen en scripts tot en met selfservice portals voor andere afdelingen dan de IT. Als programmeurs bijvoorbeeld een testserver nodig hebben, kunnen ze in een mum van tijd een VM via een website configureren.
Hypervisors draaien weliswaar op servers, maar hun aparte interfaces en API’s zijn verbonden met het gehele apparatenpark. Daaronder vallen ook de datasystemen (opslag) en de routers en switches (netwerk). De systeembeheerder kan met de beheersoftware van de hypervisors niet alleen de server en de virtuele machines beheren, maar ook voor opslagruimte zorgen en IP-adressen uitdelen. Als er dus een nieuwe servermachine via een bepaald profiel wordt aangemaakt, zorgt het systeem ervoor dat de goede switchpoort wordt geconfigureerd. Ook wordt er een virtuele schijf met de gewenste capaciteit en redundantie in het opslagsysteem gereserveerd.
Flexibel, robuust, compact
Veel leveranciers hebben ecosystemen op basis van bekende hypervisors als VMware ESXi en Microsoft Hyper-V ontwikkeld. Er zijn tools en diensten voor elke taak die je maar kunt verzinnen. Back-up, replicatie, archivering, performance-analyse, cloud-integratie, boekhoudsystemen, brancheoplossingen etc.
Simpel gezegd is een gevirtualiseerde server niet meer dan een bestand. Zo’n bestand kun je eenvoudig van het ene naar het andere hardwareplatform verplaatsen. Voorwaarde is wel dat de verschillende hypervisorversies met elkaar compatibel moeten zijn. Dat heeft niet alleen voordelen voor het back-uppen of het verhelpen van mankementen, maar ook voor de migratie naar andere machines. Bij een draaiende virtuele machine is zelfs live-migratie mogelijk. Gebruikers merken daarbij hooguit dat de performance even afneemt.
Het ligt voor de hand om gebruik te maken van deze flexibiliteit. Dit is bijvoorbeeld erg handig als er hardware dreigt uit te vallen. Je kunt dan gewoon een kopie van een virtuele machine op een ander systeem starten. De kopieën van een virtuele machine worden met korte intervallen automatisch bijgewerkt. Ook zijn er automatische controlesystemen die kijken of een VM bereikbaar is. Daarnaast zorgen ze ervoor dat er in geval van een defect automatisch naar een kopie wordt geswitcht. De kopie krijgt daarbij hetzelfde IP-adres.
Voorbeeld
Als je bijvoorbeeld een server hebt met twee fysieke processors, 48 cpu-cores en 512 GB RAM, kun je daar enkele honderden virtuele desktopmachines parallel op draaien. Wanneer al deze virtuele machines in grote lijnen identiek zijn, besparen processen zoals deduplicatie en compressie bijzonder veel opslagruimte. Bij bijvoorbeeld virtuele desktops met dezelfde Windows-versie is het grootste deel van alle databestanden van een VM identiek. Voor de deduplicatie berekent de opslagsoftware voor het opslaan van elk datablok een hashwaarde. Deze wordt met de andere gegevens vergeleken. Komt hij een blok tegen dat al bestaat, dan hoeft het systeem hier alleen maar een verwijzing naar te maken.
Bij deduplicatie moet het opslagsysteem elk geschreven datablok eerst tijdelijk opslaan. Vanwege de bijzonder hoge schrijfbelasting gebruikt het systeem hiervoor ssd’s. Nog minder vertraging is mogelijk wanneer elk datablok voor deduplicatie alleen naar het werkgeheugen wordt weggeschreven. Dit heet on-the-fly deduplicatie. Een nadeel hiervan is wel dat er gegevens verloren kunnen gaan wanneer de stroom uitvalt. Traditioneel RAM-geheugen moet immers continue onder spanning staan. NVDIMM’s met een continue flash-back-up of nieuwe geheugentypen zoals 3D XPoint moeten dit voorkomen. Met compressie kunnen de bestanden nog verder worden verkleind. Indien je de gegevens wilt versleutelen, kun je dat het best na compressie doen. Willekeurig versleutelde datablokken kunnen immers niet verder gecomprimeerd worden.
Bottleneck
Wanneer er veel virtuele machines gelijktijdig een opslaglocatie benaderen, ziet de opslag dit niet meer als sequentiële benaderingen. Het wordt dan beschouwd als een spervuur van willekeurige benaderingen (random access). Hoe korter de opslagvertraging, des te meer VM’s op een systeem met een acceptabele reactiesnelheid kunnen draaien. Om die reden is flashopslag in de vorm van ssd’s bij virtuele servers inmiddels standaard. SATA- en SAS-ssd’s worden tegenwoordig verdrongen door de snellere PCI-Express (PCIe-) ssd’s. De controller van de laatste maakt namelijk gebruik van het non-volatile memory express (NVMe)-protocol. Dit is geoptimaliseerd om veel parallelle benaderingen te verwerken.
Wanneer veel virtuele machines een centraal opslagsysteem benaderen, genereert dit veel netwerkverkeer. Vroeger was het gebruikelijk om het dataverkeer voor het opslagsysteem te scheiden van de gebruikersgegevens van de virtuele machines. Dit werd mogelijk met een Storage Area Network (SAN) met FibreChannel (FC)-techniek. Het laatste is inmiddels verdrongen door opslagprotocollen via ethernet zoals iSCSI of FCoE. Sommige bedrijven gebruiken zogenaamde convergente adapters, die zowel opslag- als ethernetverkeer via Infini-Band (IB) leiden. Ze kunnen ook propriëtaire adapters gebruiken. Een voorbeeld hiervan is Cisco’s Unified Fabric. De laatste jaren is er een trend om snelle ethernetadapters te gebruiken. Deze hebben meerdere 10GbE-poorten per servernode, of zelfs 25, 40 of 100 GbE.
Ook de snelste verbinding haalt niets uit wanneer het centrale opslagsysteem traag is. Bij oudere opslagsystemen werd met name rekening gehouden met de uitbreidmogelijkheden van de opslag. De controllers hadden daarbij onvoldoende rekenkracht en ook te weinig hoogwaardige PCIe-slots om de I/O-performance te verhogen.
Scale-out-storage
Bij scale-out-storage-systemen ligt dat anders. Daarbij worden nodes met een bepaalde opslagcapaciteit en een bijpassend aantal netwerkpoorten gecombineerd. Met elke module die wordt toegevoegd, wordt dan ook de opslag- en netwerkcapaciteit groter. Een gedistribueerd bestandssysteem zorgt ervoor dat de gegevens in een unified namespace voor alle servers bereikbaar zijn. Door deduplicatie en compressie daalt de behoefte aan fysieke opslag dermate dat de capaciteit van snelle ssd’s al prima is.
Door adaptieve optimalisering worden de gegevens over de betreffende opslagmedia verdeeld. Deze verdeling hangt af van hoe vaak ze worden benaderd. Als de ‘hotte’ gegevens niet meer in het werkgeheugen passen, worden ze naar de snelste ssd’s verplaatst. Voor schrijfacties worden zeer krachtige ssd’s gebruikt. Gegevens die minder vaak worden opgeroepen, staan op goedkopere ssd’s of zelfs harde schijven (cold storage). De verschillende opslagmedia worden in zogenaamde storage tiers ingedeeld; de optimaliseringsprocedure wordt auto tiering genoemd.
Alles in een
Met de combinatie van rekenkracht en opslag in modulaire scale-out-systemen lost HCI meerdere problemen in een keer op. De bottleneck van het netwerkverkeer wordt bijvoorbeeld grotendeels verholpen wanneer de beheersoftware de gegevens van alle virtuele machines zoveel mogelijk op dezelfde server zet. Dankzij deduplicatie en compressie kan prijzig flashgeheugen optimaal worden ingezet. En omdat alles op hetzelfde systeem draait, kunnen adaptieve algoritmen de prestaties ook afhankelijk van de belasting optimaliseren.
Beheerders hoeven zich dankzij de unified beheerinterface niet meer te verdiepen in allerlei verschillende tools voor opslagsystemen en routers. Voor routinetaken bieden HCI-aanbieders blauwdrukken, opleidingen en ondersteuning aan. Systemen kunnen snel worden ingezet, zijn eenvoudiger in het beheer en met scale-out-modules uit te breiden. Naar verluidt zijn de te verwachte prestaties van het gehele systeem makkelijker te realiseren dan wanneer je meerdere systemen van verschillende producenten zou combineren. Dat heeft bovendien het voordeel dat je bij problemen met minder verschillende personen contact op hoeft te nemen. Ook wordt het automatiseren makkelijker, omdat de software servers, opslag en het netwerk combineert.
De keerzijde is dat je je afhankelijk maakt van de HCI-provider. De verschillende HCI-concepten zijn namelijk niet volledig compatibel en bovenal zijn er duidelijke verschillen. Zo is bij VMware vSAN de opslagsoftware in de hypervisor geïntegreerd. Bij Nutanix en Atlantis Computing draait deze in een aparte virtuele machine op elke node. Atlantis maakt het weer mogelijk servernodes met verschillende opslagtypen te combineren, bijvoorbeeld servers met harde schijven en met alleen ssd’s. Bij DataCore-software kun je dan weer alle bestaande opslagsystemen integreren.

Redundantie
HCI heeft diverse niveaus van redundantie. Dat begint al bij de hardware: in een typisch scenario worden HCI-machines in een rack gebouwd waar ze de hoogte van twee standaardunits (2U) in beslag nemen. In deze ruimte draaien vier onafhankelijke servernodes met elk een eigen processor, geheugen, ssd’s en harde schijven en netwerkadapters. Twee voedingen met aparte aansluitingen voorzien de vier nodes van stroom. In plaats van een klassieke RAID-hostadapter zijn de ssd’s en harde schijven door de opslagsoftware over alle nodes met elkaar gekoppeld. Redundante gegevens worden via algoritmes berekend en samen met de gebruikersgegevens over de opslagmedia verdeeld.
Over het algemeen kun je aangeven welke mate van redundantie (uitval van een of twee nodes tegelijk) wenselijk is. Ook kun je bepalen waar de kopieën van redundante gegevens moeten worden opgeslagen. Op een tweede machine in hetzelfde of een ander rack of zelfs in een ander rekencentrum. Bovendien neemt het dataverkeer vanwege de gelijkmatig verdeelde kopieën van gegevens aanzienlijk af als je een VM van de ene naar de andere servernode wilt verplaatsen. Redundantie kan ook worden toegepast op een volledige virtuele machine. In het geval van VMware Horizon controleert een witness-instance regelmatig of een virtuele machine nog leeft en op queries reageert. In het geval een node of netwerkpoort uitvalt start de witness deze automatisch op een andere node in het redundante bestandssysteem. Ook de netwerkpoort wordt omgeleid.

Goed ingepakt
Met hierboven genoemde HCI-systemen kun je veel rekenkracht in een kleine ruimte kwijt. Elk van de vier nodes in de BigTwin van Supermicro kan worden uitgerust met 3 TB werkgeheugen en twee Xeon-cpu’s. Samen beschikken ze dan over 44 cores en 88 threads. Je bent dan alleen aan processors en geheugen al 44.000 euro per node kwijt. Een meer gangbare configuratie bestaat uit twee 16-core cpu’s en 512 GB RAM per node. Inclusief ssd’s betaal je dan voor een configuratie van vier systemen voor de hardware zo’n 100.000 euro. Daarmee zou je in de praktijk 500 tot 800 virtuele desktops kunnen draaien.
Als je dan 16 van deze 2U-units in een 42U-rack plaatst – je moet er tenslotte ook nog enkele netwerkswitches bij zetten – heb je 2048 cpu-threads en 32 TB RAM beschikbaar. Daarin kun je enkele duizenden virtuele machines draaien. Het hele grapje kost dan 1,5 miljoen euro, waar nog aanzienlijke licentie- en supportkosten bijkomen. VMware biedt de Hypervisor VMware ESXi aan vanaf 2450 euro per cpu, met vSAN kost het meer. Dit zijn dan ook systemen voor grote bedrijven.
Voor kleinere bedrijven of filialen zijn goedkopere HCI-configuraties verkrijgbaar. Met de ‘vSAN TCO and Sizing Calculator‘ van VMware kun je een inschatting maken van de benodigde hardware en licentiekosten.
Meer dan een hype
HCI combineert moderne technieken. Virtualisatie, software-defined storage, flashgeheugen en snelle ethernetadapters. Moderne servers met krachtige multicore-cpu’s ondersteunen veel werkgeheugen en talrijke PCIe-lanes voor ssd’s en ethernetverbindingen. Daarmee kunnen ze de benodigde bronnen beschikbaar stellen. De omschrijving ‘hyperconvergentie’ is misschien wat hoogdravend, maar het succes bevestigt het concept. Bij enkele toepassingsgebieden biedt het samenbrengen van servers, massaopslag en beheersoftware aanzienlijke voordelen.
HCI is echter niet in alle gevallen zaligmakend. Soms zijn er ook dramatische verschillen tussen de oplossingen van verschillende makelij. Als je een oplossing zoekt die afwijkt van de standaard, moet je opletten of er bottlenecks of verborgen kosten op de loer liggen.

Tip

Krijg direct toegang tot alle beschikbare edities op je laptop, tablet of smartphone.



Praat mee