


Eigenlijk doen taalmodellen niets anders dan het vinden van het meest waarschijnlijke volgende woord. Desondanks vormt de technologie daarmee de basis voor een nieuwe potentiële AI-revolutie: autonome AI-agents die zelf oplosstrategieën verzinnen voor problemen, ze uitvoeren en hiervoor externe tools inzetten.
Wat kan AI echt doen?
Grote taalmodellen zijn inmiddels al geslaagd voor de Turingtest uit 1950: ze imiteren menselijke dialogen bijna perfect. En nog voordat het publiek de kans heeft gehad om dit echt te verwerken, vraagt de snelle ontwikkeling van autonome AI-agents alweer om de volgende test.
In plaats van alleen maar te communiceren, moet AI zelfstandig complexe taken kunnen oplossen. Mustafa Suleyman, medeoprichter van DeepMind en CEO van Microsoft AI, stelt voor om agents een startkapitaal te geven en te kijken of en hoe het ze lukt om daarmee winst te maken – van het bedrijfsplan en de productontwikkeling tot reclame en online verkoop. De cruciale vraag verschuift dus van ‘Wat kan een AI zeggen?’ naar ‘Wat kan een AI doen?’
De technologie is nog ver verwijderd van het doorstaan van zo’n test. Niettemin geven de grandioze aankondigingen van de industrie onder het overmatig gebruikte modewoord ‘Agentic AI’ een idee van waar de reis naartoe gaat.
Softwareproducent Salesforce is sinds de herfst van 2024 bezig met de ontwikkeling van het Agentforce platform. E-commercebedrijven kunnen dat gebruiken om AI-agents te configureren die bijvoorbeeld productvragen of garantieclaims van klanten verwerken en toegang hebben tot externe diensten zoals financiële transacties. In de toekomst zullen ze de klantenservice volledig digitaal afhandelen.
De ChatGPT-agent gaat een vergelijkbare kant op. Volgens de producent Open AI is de ChatGPT-agent ontworpen om complexe kennistaken uit te voeren door apps zoals Gmail en GitHub met elkaar te verbinden en om zelfstandig te vragen om aanvullende details als een taak onduidelijk mocht zijn.
De agent kan bijvoorbeeld zelfstandig een agenda raadplegen om een afspraak in te plannen, zoeken naar een restaurant met het gewenste menu en prijsklasse, en een tafel reserveren.
Microsoft fantaseert ondertussen over een toekomst waarin elk bedrijf Copilot Studio gebruikt om zijn eigen AI-agents te bouwen die autonoom acties uitvoeren en een heleboel andere agents aansturen. Agents zullen niet alleen vakantiebestemmingen voorstellen, maar ook hotels en reistickets boeken.
De ontwikkeling op dit gebied is in een stroomversnelling geraakt dankzij het Model Context Protocol (MCP) van Anthropic. Dat is bedoeld om de uitwisseling van gegevens tussen AI-toepassingen en andere gegevensbronnen te standaardiseren en te vergemakkelijken (zie bijvoorbeeld dit artikel over het Model Context Protocol).
Taalmodellen als tussenpersoon
Het uitgangspunt voor deze ontwikkelingen is het besef dat de natuurlijke taal van grote taalmodellen bij uitstek geschikt is als uitwisselingsformaat tussen de componenten van een agent. En omdat LLM’s, in tegenstelling tot eerdere architecturen, al een bepaalde hoeveelheid wereldkennis hebben gecodeerd, kunnen ze taken op zich nemen die met conventioneel programmeren niet zo eenvoudig op te lossen zouden zijn.
“Het was een nogal grote verassing toen eenmaal duidelijk werd dat taalmodellen in hoge mate in staat zijn individuele stappen strategisch te kunnen inplannen om grotere problemen op te lossen,” zegt Jakob Nikolas Kather, hoogleraar aan de TU Dresden. “Nu zijn we voor het eerst in de menselijke geschiedenis getuige van de opkomst van steeds autonomer wordende hulpmiddelen die ook zelfstandig hun mogelijkheden kunnen uitbreiden.”

In hun eenvoudigste vorm zijn agents op basis van taalmodellen al wijdverspreid. De meeste grote commerciële modellen kunnen een zoekopdracht op internet uitvoeren, waarmee ze in feite al een extern hulpmiddel gebruiken. Ze kunnen ook wiskundige problemen oplossen.
Als een model niet in staat is om een wiskundeprobleem te beantwoorden op basis van zijn trainingservaring, herkent het dit en schrijft het in plaats daarvan een stuk code om het probleem op te lossen. Een agent voert de code uit en geeft het resultaat door aan de LLM, die het in natuurlijke taal aan de gebruiker presenteert.
Voor complexere problemen kunnen langere conversaties worden onderhouden waarin het taalmodel communiceert met een willekeurig aantal andere programma’s totdat het uiteindelijk tot een resultaat komt.
Het team van Dr. Tobias Wirth bij DFKI heeft een schema opgesteld van hoe een AI-agent is opgebouwd (zie kader). De LLM zelf doet alleen wat hij altijd heeft gedaan. Hij vult de tekst aan die als prompt is ontvangen. Of dit nu in de vorm van natuurlijke taal of programmacode is, doet er nauwelijks toe, want hij is met beide getraind.
Inwendige werking van een AI-agent
De belangrijkste bouwsteen voor AI-agents zijn grote taalmodellen. Ze leveren de nodige kennis om flexibel en autonoom te interageren met de wereld. Het blokschema illustreert de structuur van een agent-systeem dat informatie analyseert en zelf beslist welke tools het moet gebruiken om een complexe vraag te beantwoorden. Het kan databases doorzoeken, op internet naar aanvullende informatie zoeken en het resultaat per e-mail versturen.
Het diagram is gemaakt door ontwikkelaar David Riebschläger en projectmanager Christoph Maerz in de groep ‘Generative & Transparent AI’ onder leiding van Dr. Tobias Wirth bij het Duitse onderzoekscentrum voor kunstmatige intelligentie (DFKI). Het begin- en eindpunt is de gebruikersinterface, die het verzoek ontvangt en het antwoord van het systeem terugstuurt. De aanvraag wordt eerst vertaald naar de Engelse voertaal omdat het hele systeem hiervoor ontworpen is. Documenten die worden ingelezen worden ook vertaald.
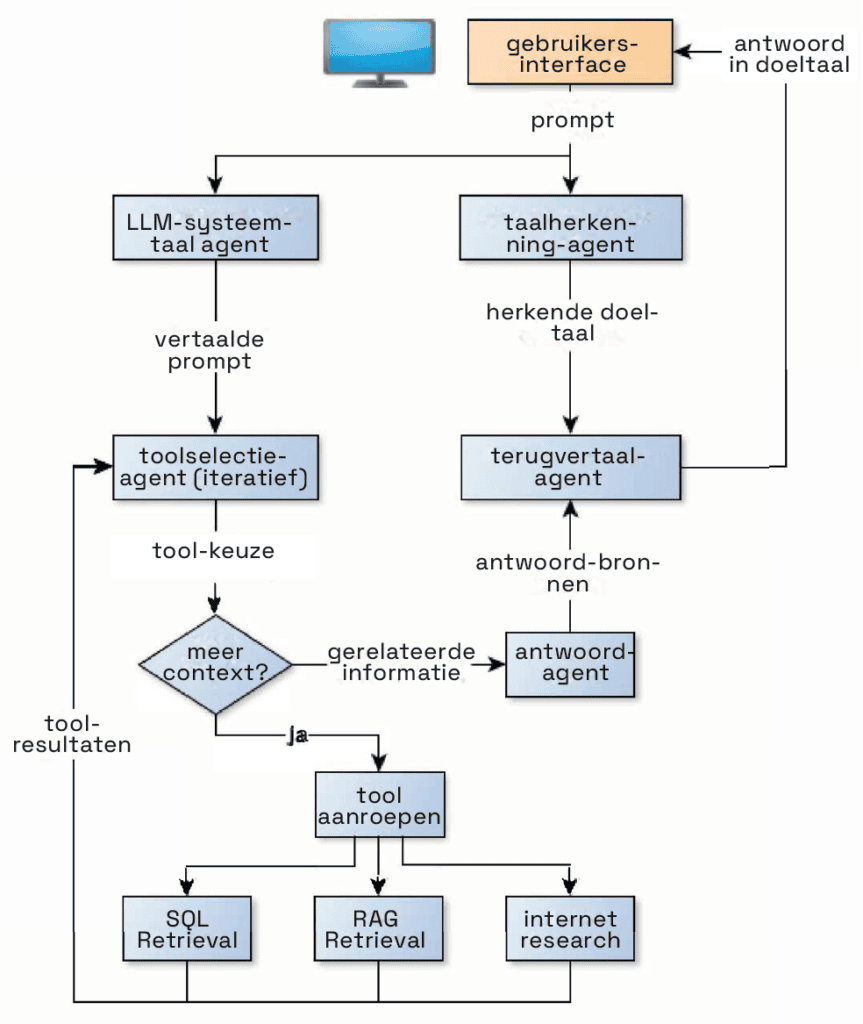
De iteratieve toolselectie-agent is het middelpunt van het agentsysteem. Het taalmodel krijgt via een systeemprompt de opdracht om taken op te splitsen in zinvolle subtaken en deze te delegeren naar de beschikbare tools.
Als de vraag betrekking heeft op informatie in de database, wordt deze naar de SQL Retrieval-tool gestuurd. Het taalmodel dat zich daar bevindt, koppelt de tekstuele verklaring aan kennis over de structuur van de database. Het formuleert een SQL-query waarmee de database wordt doorzocht. Als de query ook de opdracht bevat om het resultaat naar het e-mailadres van een specifieke persoon te sturen, roept de toolselectie-agent tegelijkertijd het Retrieval Augmentation Generation-systeem (RAG) op om in de daar opgeslagen gegevens naar het gewenste adres te zoeken. Of het start de internet research-tool om het adres te vinden.
Alle gevonden informatie wordt teruggestuurd naar de toolselectie-agent, die vervolgens beslist of er nog vragen onbeantwoord blijven en of er opnieuw een tool geactiveerd moet worden. Zo niet, dan wordt de verzamelde informatie naar de response agent gestuurd, die de nodige conclusies trekt om de vraag te beantwoorden. De terugvertaal-agent vertaalt vervolgens het antwoord vanuit de systeemtaal terug naar de doeltaal. Uiteindelijk komt dit antwoord terecht in de chat van de gebruiker.
Medische AI-agents
Kather, wiens onderzoekswerk plaatsvindt op het grensvlak van informatica en geneeskunde, heeft al AI-systemen ontwikkeld voor medische toepassingen. Tot nu toe waren deze echter alleen nuttig voor specifieke toepassingsgebieden. Sommige algoritmen konden bijvoorbeeld tumoren detecteren op röntgenfoto’s, terwijl andere algoritmen artsen hielpen bij het zoeken in databases naar medische artikelen.
“Er zijn duizenden verschillende taken in de dagelijkse klinische praktijk,” zegt Kather. “Daarom brengen we deze bestaande modules nu samen en maken we ze als tools beschikbaar voor onze AI-agent. Centraal staat een groot taalmodel waaraan artsen complexe taken kunnen toewijzen.
De agent heeft eerst toegang tot de schat aan kennis in een database met klinische studies en richtlijnen die hem ter beschikking is gesteld en herkent dan zelfstandig of er in een bepaald geval bijvoorbeeld naar een tumor in de longen moet worden gezocht. Zo ja, dan roept het een radiologiemodel op dat gespecialiseerd is in longanalyse, laat het de beelden beoordelen, haalt het resultaat op en beslist op basis daarvan over de volgende stap.
“Het bijzondere is dat de agent flexibel kan reageren op de respectievelijke eisen,” zegt Kather. “Deze aanpak werkt bijzonder goed en kan ook complexe vraagstukken in kaart brengen.”

Kather en zijn team hebben voor elke module een interface gedefinieerd om hun agent uit te leggen welke tools beschikbaar zijn en hoe hij ze kan gebruiken. De externe modules vereisen immers verschillende invoer. De feedback kan ook verschillend zijn en naast tekst bijvoorbeeld numerieke waarden of binaire ja/nee-antwoorden bevatten.
“In het eenvoudigste geval is het voldoende om het centrale taalmodel te voorzien van een systeemprompt waarin de afzonderlijke hulpmiddelen in natuurlijke taal worden beschreven,” legt Kather uit. “Moderne taalmodellen zijn immers toch al specifiek geoptimaliseerd voor het gebruik van tools.”
Voorzichtigheid en experimenteren
Voorzichtigheid en zorgvuldigheid zijn vereist voor medische toepassingen. Kather en zijn team definiëren precies welke problemen een agent moet oplossen en welke tools hij daarvoor mag gebruiken. Vervolgens bevriezen ze hun systeem zodat het niet kan veranderen en evalueren ze het zorgvuldig. “Alles wat we uiteindelijk in de toepassing willen stoppen, moet absoluut betrouwbaar en volledig begrepen worden,” benadrukt Kather.
Hij is echter niet alleen hoogleraar aan de faculteit geneeskunde, maar ook aan de faculteit computerwetenschappen van de TU Dresden. En als het gaat om onderzoek aan de computerwetenschappelijke kant, zijn wetenschappers veel meer bereid om te experimenteren.
“Er zijn nu agent-modellen die hun eigen tools en interfaces kunnen maken,” zegt hij. Als een model niet over de juiste tools voor een taak beschikt, zoekt het naar broncode in wetenschappelijke publicaties op internet om het probleem op te lossen. Als de code niet meteen werkt, kunnen sommige systemen deze repareren in een iteratief proces. Dit werkt al verrassend goed, zegt Kather.
Leren van het Atari-spel
Professor Kristian Kersting, die aan het hoofd staat van de afdeling Machine Learning aan de Technische Universiteit van Darmstadt, traint AI-agents om Atari-videospellen uit de jaren tachtig te spelen.

Die dienen als populaire testplatforms voor reinforcement learning, waarbij een agent willekeurig strategieën uitprobeert volgens de trial-and-error-methode en wordt beloond bij succes. De beloning is gebaseerd op de score, die naast de pixels op het scherm de enige invoerwaarde voor de agents is.
Uitsluitend uitgerust met dit vermogen en zonder enige achtergrondkennis van de game zelf, leerden agents van het Deep-Q-Network (DQN), ontwikkeld door DeepMind, al in 2015 om Atari-klassiekers onder de knie te krijgen, van Tennis, Pong tot Space Invaders aan toe.
AI-agenten spelen SeaQuest
Sommige agents ontwikkelden ongebruikelijke strategieën die zelfs hun ontwikkelaars verrasten en in de meeste games het niveau van menselijke speltesters overtroffen. In sommige spellen slaagde DQN er echter niet in om een succesvolle strategie te ontwikkelen alleen op basis van de pixels op het scherm. En juist zulke spellen zijn interessant voor ontwikkelaars van AI-agents.
Kersting noemt het spel SeaQuest voor de Atari 2600 als een uitdaging. Daarin bestuur je een onderzeeër die duikers uit zee vist, wordt aangevallen door haaien en af en toe naar de oppervlakte moet om zijn zuurstoftank bij te vullen.
“Als ik wil dat een agent zijn spelomgeving echt begrijpt, is deze informatie niet genoeg,” zegt Kersting. “Het is immers heel moeilijk om aan de hand van de afzonderlijke pixels op het scherm te begrijpen dat een balkje dat steeds korter wordt, een slinkende zuurstofvoorraad representeert.” Samen met zijn collega’s Hikaru Shindo en Quentin Delfosse werkt Kersting aan het combineren van de agents met taalmodellen onder de naam BlendRL.
‘RL’ staat voor reinforcement learning en ‘Blend’ voor de mix van twee verschillende manieren waarop de agents tot hun beslissingen komen: de beelden van het spel worden direct als pixels in het neurale netwerk ingevoerd, zoals in DQN, of de agent analyseert de scène voordat hij een actie onderneemt.
“Dit is geïnspireerd door het werk van Daniel Kahneman,” zegt Kersting. Deze psycholoog, die in 2024 overleed, identificeerde twee basistypen van besluitvorming bij mensen. ‘Systeem 1’ staat voor instinctieve, snelle actie, terwijl ‘Systeem 2’ wordt gekenmerkt door langdurige reflectie en beraadslaging.
In het geval van Kerstings SeaQuest-agents betekenen Systeem 1-beslissingen het onmiddellijk reageren op een dreiging in gevaarlijke situaties, zoals wanneer een haai nadert. Het tijdrovendere Systeem 2 wordt gebruikt bij de strategie voor de zuurstoftank.
De agent haalt objecten zoals onderzeeërs, duikers en zuurstoftanks uit de invoerpixels. Hiervoor heeft hij rechtstreeks toegang tot de objectrepresentatie in het interne geheugen van de Atari 2600 of gebruikt hij een beeldherkenningsmodel. Vervolgens kan hij de spelomgeving logisch beschrijven en een strategie formuleren. “Er is op dit moment geen haai in de buurt van de onderzeeër, dat zou een goede gelegenheid zijn om naar de oppervlakte te gaan.”

Een derde systeem op een hoger niveau beslist of de agent in een bepaalde situatie beter kan werken met de pixels volgens systeem 1 of met objecten volgens systeem 2. In de toekomst moet het helpen om vooraf kennis te verzamelen. In de huidige versie van BlendRL moeten de onderzoekers dit soort informatie nog expliciet invoeren.
“We zijn echter al bezig om de agents in staat te stellen om zelf spelregels te leren,” zegt Kersting. “Er zijn immers ook spelbeschrijvingen voor deze spellen die dergelijke instructies bevatten, die de agent ook daar zelf zou kunnen lezen.”
Gebruik in robotica
De agent-benadering van Kersting zou nuttig kunnen zijn in de robotica. Autonome robots zouden zich bijvoorbeeld ook moeten oriënteren op basis van de systemen 1 en 2 van Kahneman en afhankelijk van de situatie anders moeten reageren op de informatie die ze van hun sensoren krijgen.
Volgens het beschreven systeem 2 kunnen ze relaties tussen echte objecten herkennen en verwerken. Het kan echter nog wel even duren voordat robots zelfstandig hun weg kunnen vinden in de wereld, omdat de werkelijkheid veel complexer is dan een digitale testopstelling.
Aan de softwarekant kunnen sommige AI-agents zichzelf al verbeteren door gebruik te maken van de wereldkennis in hun taalmodellen. Gezien het tempo waarin de wetenschap en de industrie AI-toepassingen in andere disciplines ontwikkelen, zullen er waarschijnlijk op korte termijn steeds meer krachtige AI-agents verschijnen.
Thomas Brandstetter en Marco den Teuling



Taalmodellen zoeken niet naar het volgende woord maar naar de volgende token. Dat is een wezenlijk verschil. Een LLM weet namelijk niet wat een woord is. Een LLM weet überhaupt niet wat het zegt. Een LLM heeft geen idee dat het bestaat. Het weet niets. Het heeft geen gevoel, geen gedachten, geen intenties, geen plannen. Een LLM heeft net zoveel verstand als een politicus: geen. Het enige wat een LLM ziet, zijn getallen. Die is niet betrokken bij een gesprek. Die voert zelfs geen gesprek. Die sorteert tokens. Meer onpersoonlijk kan het nauwelijks worden. Wat veel mensen daarnaast niet begrijpen,… Lees verder »
Zou je trouwens gelijk hebben en je kan me een 16 bitter presenteren met 48kB RAM, stuur ik je een taart ter excuses van mijn lompe bericht en mijn onwetendheid.
De werkdruk op de redactie geeft geen ruimte voor lange verhalen hier, maar om je kruistocht te helpen beëindigen 😊 zal ik even kort reageren. Het ging om een ZX Spectrum met een Zilog Z80A-processor. Dat een 16-bit systeem noemen is een hyperbool: de processor had 16-bits registers, bewerkingen en geheugenadressering maar was verder 8-bit. Die taart mag dus achterwege blijven 😉 De 16-bit geheugenbus en andere kenmerken maakten het wel mogelijk om 64 kB geheugen te adresseren (16 kB ROM en 48 kB RAM in mijn 48K-model). Ik ben overigens benieuwd naar de hardware waarop je een 500B-model draait… Lees verder »