



Kort na de lancering van AMD’s Ryzen kwamen zowel Microsoft als Intel met nieuwe versies van hun Windows-compilers. We testten AMD’s R1800X, zijn voorganger Excavator en enkele concurrenten met die compilers en met klassieker SPEC CPU2006 en ‘struikelblok’ Flops.
Lees verder na de advertentie
AMD’s Ryzen is in eerste instantie bedoeld voor desktopgebruik. Daarom richten we ons vooral op de gangbare Windows 10-omgeving. Om code te genereren wordt onder Windows Microsofts Visual Studio-compiler het meest gebruikt. Ruim 90 procent van de gangbare Windows-software wordt met (unmanaged) MSVC-C/++ gemaakt. Intels compiler tref je onder Windows zelden aan, maar bijvoorbeeld wel bij Photoshop CC en de Cinebench-benchmark. Verder testen we met de CPU2006-suite. Die test de integerperformance met gangbare desktoptoepassingen zoals schaken, comprimeren, H.264 (de)coderen enzovoorts. Omdat de volledige broncode van de CPU2006-software beschikbaar is, kan die altijd met de nieuwste compilers voor de nieuwste architectuur gecompileerd worden.
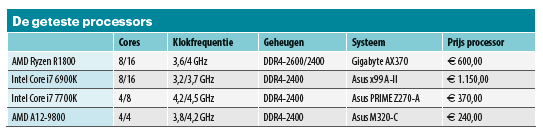
Van de Intel- en Microsoft-compilers zijn sinds dit voorjaar de definitieve 2017-versies beschikbaar. Voor de Intel-Composer 2017 met C/C++ en Fortran is dat al de tweede update. Die heeft bovendien de runtime-omgeving van Visual Studio nodig. Hij is echter nog niet afgestemd op Visual Studio 2017, maar gaat uit van de voorganger Visual Studio 2015.
Tip!

Slimme IP-camera’s met live toezicht en haarscherpe beveiliging!

De nieuwe Visual Studio 2017 houdt meer rekening met Linux. Hij kent cmake en kan makkelijk als ontwikkelomgeving voor Linux-programma’s worden ingezet. Om onnavolgbare redenen kan de Microsoft-compiler echter nog steeds niet overweg met C99, dat in de broncode van een van de CPU2006-benchmarks wordt gebruikt (de kwantumcomputersimulatie 426.libquantum). Met enkele aanpassingen aan de C(99)-broncode kan die worden omgezet naar C++ en toch gecompileerd worden. Dergelijke aanpassingen gaan echter tegen de Run Rules van SPEC in, daarom staat in de tabellen verderop het label (ong.) voor ‘ongeveer’. Libquantum is sowieso een speciaal geval omdat de Intel-compiler die code automatisch enorm kan optimaliseren. Dat leidt natuurlijk tot een mooi resultaat, maar geen goede afspiegeling van de praktijk. We vermelden alle resultaten daarom ook apart als SPECint-C/C++ zonder Libquantum.
De floatingpointsuite van CPU2006 bevat hoofdzakelijk Fortran-programma’s, maar ook zeven wetenschappelijke C/ C++-programma’s. Zoals gewoonlijk testen we uitsluitend met 64-bit code, zonder automatische parallellisatie en zonder speciale commerciële Heap-bibliotheken. Bij automatische parallellisatie krijg je namelijk geen bruikbare waarden voor single-threads en juist die geven inzicht in het aantal ‘Instructions per Clock’ (IPC). We willen juist antwoord op de vraag of Ryzen daadwerkelijk 52 procent meer instructies per kloktik verwerkt dan voorganger Excavator. En hoe doen Broadwell-E en Kaby Lake het? Dat testen we met de Microsoftcompiler.
De Microsoft Visual Studio-versies 2015 en 2017 ondersteunen AVX2 en hebben ook rudimentaire vectorisatie. Bovendien kun je een architectuur voortrekken (/favor:Intel of /favor:AMD), al ontbreekt die optie in het menu van Visual Studio. De AMD-optimalisatie schijnt alleen betrekking te hebben op Bulldozer, maar ook bij de 4e generatie daarvan (Excavator/Bristol Ridge) ontdekten we geen verschil met de standaardversie. Hetzelfde geldt voor de twee hier geteste Intel-systemen, de directe concurrent Broadwell-E (octacore Core i7-6900K) en de quadcore Kaby Lake Core i7 7700K.
SPECint en IPC
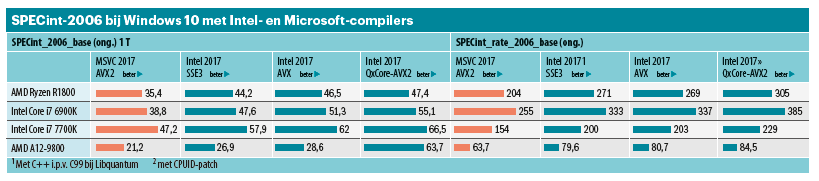
De resultaten van de Single Thread-tests: SPECint komt bij een test met de Ryzen R1800X op 3,6 GHz (4,0 GHz Boost) met AVX2-geoptimaliseerde code van MSVC 2017 tot een score van (ong.) 35,4 punten. De Excavator (3,8 Ghz met 4,2 GHz Turbo) scoort slechts 21,2 punten. Als je rekening houdt met het verschil in klokfrequentie, is de winst maar liefst 76 procent. Gebruik je geen DDR4-2600-modules bij het Ryzen- systeem maar DDR4-2400, dan valt de score 3 procent lager uit. De voorsprong bij IPC is dan nog steeds meer dan 70 procent.
Intels Core i7 6900K is met 38,8 punten ongeveer 10 procent sneller. Bij een klokfrequentie van 3,2/3,7 GHz betekent dat een 20 procent hogere IPC. De winst gaat dankzij de hoge frequenties van 4,2/4,5 GHz naar de Kaby Lake Core i7 7700K met een SPECint 1T-waarde van 47,2. Dat is echter alleen qua absolute score, want als je rekening houdt met de kloksnelheid ligt de IPC-waarde circa 7 procent onder de Broadwell-E.
Intel-compiler voor Ryzen
De Intel-compiler kun je normaal gebruiken voor AMD-processors, maar die biedt ook een speciale optie met AVX-tuning: / arch:AVX. De AVX-optimalisatie levert echter niet altijd snellere code op door de daaraan gekoppelde lagere kloksnelheid.
Met 44,2 (zonder) en 46,5 (met AVX) is de SPECint-code maar liefst zo’n 32 procent sneller dan met de Microsoft-compiler. Als je de problematische benchmark Libquantum echter uitsluit, wordt de voorsprong beperkt tot 19 procent. Bij SPECfp pakt de AVX-optimalisatie negatief uit: vooral bij 459.GemFDTD daalt de performance met meer dan 40 procent. Alles bij elkaar genomen komt de Ryzen tot een SPECfp_2006_ base-waarde van 59,9 met AVX en 61,7 zonder AVX.
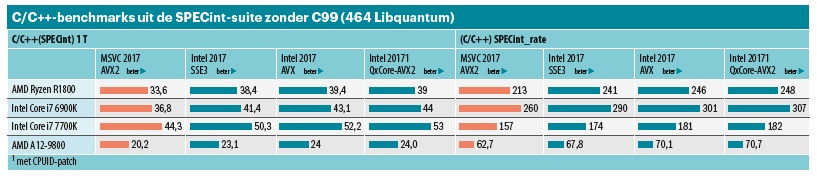
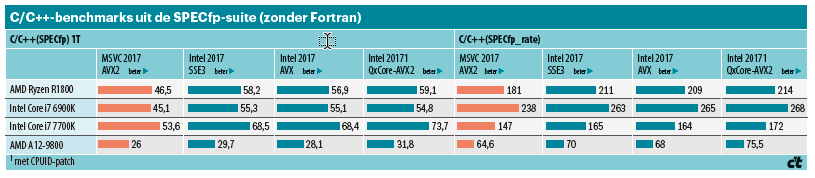
Dat maakte ons nieuwsgierig. We wilden uitzoeken waarom de AMD-processors met een optimalisatie van de Intel-compiler slechtere scores behaalden. Een kleine patch op de juiste plek deed wonderen en al snel draaiden de AMD-processors zonder merkbare problemen met de geoptimaliseerde Intel-code. Bij de SPECint-suite werd het verschil veroorzaakt door een enkele benchmark, namelijk de eerder genoemde benchmark 462.libquantum. Die ging van 211 (Blend-SSE3) en 291 (Blend-AVX) naar 409, waardoor de algehele SPECint-waarde steeg naar 47,4. Dat was precies de waarde die concurrent Broadwell-E haalde zonder AVX-optimalisatie. Met volledige optimalisatie kwam die tot 55,1 SPECint-punten.
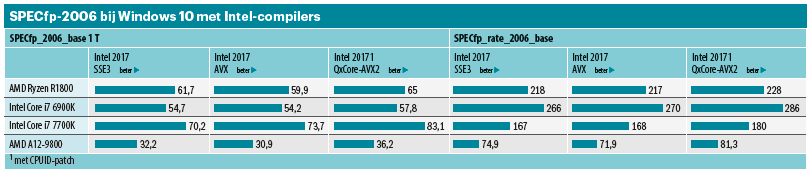
Bij SPECfp profiteren vooral drie benchmarks van de ‘speciale optimalisatie’, hoewel de winst wat bescheidener is: circa 12 tot 42 procent, terwijl 459. GemFDTD juist zo’n 25 procent verliest. In totaal stijgt SPECfp daarmee met 5 procent naar 65 punten. Dat is ten opzichte van de Excavator een stijging van 50 (SPECint) tot 63 procent (SPECfp). Nog spannender is echter het resultaat in vergelijking met de Broadwell E, want die verliest daar door zijn lagere kloksnelheid (waarbij de vier geheugenkanalen geen voordeel opleveren). Hij scoort slechts 57,8 SPECfp_2006_base, een 12 procent lagere score dan de Ryzen. De Kaby Lake met zijn hoge kloksnelheid sprint hier naar 83,1 SPECfp-punten.
Bij de SPECRate-waarden met 16 threads blinkt de Broadwell-E daarentegen uit met zijn vier geheugenkanalen. Hij verslaat met de zwaar geoptimaliseerde Intel-code de Ryzen duidelijk met 385/286 tegenover 305/228 SPECint/fp_ rate_base2006. De quadcore Kaby Lake (229/180) kan daar niet meekomen en de Excavator (71,8/75,5) speelt in een hele andere divisie. De scores zijn circa 50 procent hoger dan SPECint_rate_base2006 (ong.) met Microsoft-code: 204 punten bij Ryzen en 255 bij Broadwell-E. Dat klinkt dramatischer dan het in de praktijk is, want zonder Libquantum is het verschil nog maar iets meer dan 20 procent.
De single-thread-benchmarks hebben we bij de Ryzen RX1800X uitgevoerd met door AMD geleverde 8GB-DRAM-modules met DDR4-2600. Dat ging grotendeels zonder problemen, maar bij volle belasting met 16 threads en 32 gigabyte geheugen klaagde de suite relatief vaak over ‘miscompares’. Het systeem doorliep daar geen complete test mee, zodat we moesten overstappen op DDR4-2400 modules.
Topologie-mengelmoes
Van de geheugenbenchmark Stream van John McCalpin (geschreven in pure C met OpenMP 2.0) hebben we de meest recente versie 5.10 gebruikt. Bij het compileren moet je de matrixgrootte zo kiezen dat die steeds minimaal het viervoudige is van de L3-cachegrootte. De benchmark is geschikt voor zwaardere serverprocessors en gebruikt 300 MB per matrix. Voor de performance komt het erop aan dat je de juiste compiler gebruikt en het juiste aantal threads aan de verschillende cores toewijst. Maar wat is de juiste compiler? Voor Stream-Triad is dat ongetwijfeld de Intel C/ C++-compiler. Zowel MSVC 2017 als GCC 6.2 onder Linux presteren duidelijk minder. Die werken niet optimaal met prefetching om de drie streams in stand te houden.
Het juiste aantal threads en de toewijzing ontdek je door te experimenteren. Het is daarbij handig als je weet hoe de fysieke en logische cores opgebouwd zijn. Dat is bij Ryzen geen kinderspel. Aanvankelijk werd de Windows 10-scheduler zelfs verweten de toewijzing niet goed af te handelen. Die scheduler gedroeg zich inderdaad wel een beetje vreemd, maar dat is een andere kwestie. Windows 10 benut de logische cores wel correct, zoals het uitlezen van GetLogicalProcessorInformation() laat zien.
Er zijn echter talloze programma’s die niet op Windows vertrouwen en zelf de topologie willen herkennen. Dat gaat bij Ryzen vaak mis. Het probleem zit hem in de gebruikte algoritmen voor het herkennen van de topologie. De zowel door Intel als lange tijd door AMD gebruikte ‘Processor and Core Enumeration Using CPUID’ leidt bij Ryzen tot een verkeerde herkenning en daardoor vaak slechte optimalisatie. Zelfs AMD’s eigen tool enum.c uit 2013 herkent Ryzen verkeerd, net als Intels OpenMP: de een ziet 16 fysieke cores, de ander een enkele core met 16 threads …
Intels OpenMP kun je toch gebruiken als je de toewijzing via de omgevingsvariabele KMP_AFFINITY expliciet regelt. OpenMP vanaf versie 4.0 biedt daar ook OMP_PROC_BIND en OMP_PLACES voor. Maar helaas, Microsoft ondersteunt alleen het 15 jaar oude OMP 2.0 uit 2002.
Bandbreedte benut
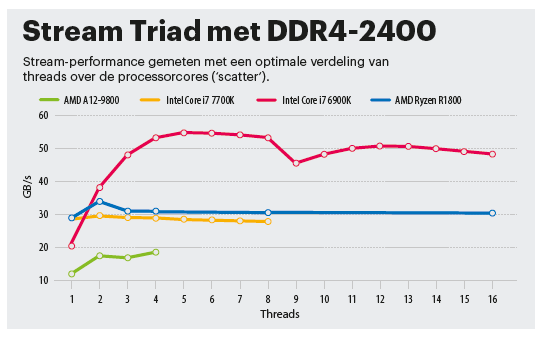
DDR4-2400 biedt per kanaal een theoretische bandbreedte van 19,2 GB/s. Stream-Triad gebruikt echter twee streams tegelijkertijd voor het lezen en een enkele voor schrijven, waardoor de praktijkresultaten wat bescheidener zijn. De R1800X verdeelt de data ook bij slechts een enkele thread efficiënt en komt daarmee tot 28,6 GB/s. De Excavator op het Bristol Ridgeplatform zou volgens de documentatie ook een dual-channel DDR4-geheugencontroller hebben, maar in ons testsysteem Asus M320-C haalt hij met een enkele thread slechts 12 GB/s. Zelfs met alle vier de cores komt hij niet verder dan 18,6 GB/s.

Bij Ryzen zijn twee threads voldoende voor de volledige bandbreedte. Als die draaien als SMT-duo op dezelfde core, halen ze 29,6 GB/s, verdeeld over twee cores in hetzelfde corecomplex (CCX) wordt dat 32,4 GB/s. Het beste resultaat krijg je als de twee threads over de twee CCX’en verdeeld zijn. Dan komt het resultaat op 33,8 GB/s. Zet je alle 16 threads aan het werk, dan daalt de performance met circa 10 procent tot 30,5 GB/s.
Een vergelijkbaar beeld zien we bij de Kaby Lake Core i7-7700K. Met een enkele thread loopt de stream met 28,5 GB/s. Dat loopt op tot 29,5 GB/s (2 threads) en daalt daarna langzaam tot 27,8 GB/s (acht threads).
De Broadwell-E is rijkelijk voorzien van vier geheugenkanalen, maar komt bij een enkele thread langzaam op gang met slechts 21,1 GB/s. Het is dus geen wonder dat de single-thread-performance relatief zwak is. Met twee threads streamt hij echter al met 38 GB/s. En bij vier threads, optimaal verdeeld over de fysieke cores, komt hij pas echt op gang tot hij zijn maximum bereikt van bijna 55 GB/s. De gevolgen daarvan zie je ook terug bij SPECrate.
De op HPC-gebied zo populaire Linpack-benchmark hebben we achterwege gelaten omdat die in eerste instantie afhankelijk is van de kwaliteit van de BLAS-library. Zolang AMD op dat gebied niets fatsoenlijks heeft, is een vergelijking zinloos. We kregen de zwaar geoptimaliseerde Intel-AVX2-Linpack-versie via een Patch wel grotendeels aan de praat op Ryzen, maar de resultaten weken te veel af van wat theoretisch haalbaar is.
Flops in plaats van Linpack
De SMP Linpack-score berust grotendeels op de matrixvermenigvuldiging DGEMM. Die maakt bij nieuwere processors weer gebruik van de gecombineerde vermenigvuldiging/ optel-instructie (FMA) van de AVX-units. De daadwerkelijk behaalde pure FMA-score is een indicatie voor wat bij Linpack haalbaar is. Je moet daar minstens 90 procent van halen als de benchmark echt goed gecompileerd is. Het Flops-programma van Google-programmeur Alex Yee doet exact dat soort FMA-benchmarks. Hij was ook verantwoordelijk voor het bekende y-cruncher, waarmee Pi en e tot op een biljoen decimalen berekend kunnen worden. Het Flops-programma leidde tot grote problemen omdat Ryzen bij duurbelasting met FMA-instructies van 3 operanden (FMA3) crashte. Ons gigabyte-testsysteem is echter voorzien van een nieuwer BIOS en nieuwe microcode (0x80000111c), waardoor het Flops-probleem verleden tijd is. Het probleem deed zich trouwens niet met alle gecompileerde code voor, alleen als daadwerkelijk FMA-instructies zonder enige tussenpauze gegenereerd werden. Dat was het geval bij Microsoft MSVC 2015 en 2017.
Compiler-afhankelijk
Yee gebruikt zogeheten intrinsics, een soort in C beschikbare assembler-instructies. Daardoor zou je kunnen denken dat de resultaten compileronafhankelijk zijn, maar dat is niet het geval. De compiler moet ook de registers beheren en dat heeft Microsoft duidelijk beter voor elkaar dan Intel. Bijzonder duidelijk is dat bij Flops-benchmarks met gescheiden vermenigvuldigen en delen. Bij het disassembleren van de Intel-code zie je daarbij talloze geheugenaanroepen, terwijl die bij Microsoft nauwelijks nodig zijn. Daardoor loopt de Microsoft-code ruim 50 procent sneller. Bij FMA3 zijn ze ongeveer even snel. Ryzen ondersteunt net als Excavator en Piledriver ook FMA4, waarbij geen bronregister overschreven wordt. Daar biedt echter alleen de Microsoft- compiler intrinsics voor. FMA4 is zo’n twee procent trager dan FMA3. Zoals bekend heeft Ryzen slechts een 128-bit busbreedte en AVX-eenheden, waardoor de performance per core bij die benchmarks niet kan concurreren met Intel. Bij 256-bit FMA3 (DP) halen de acht fysieke cores 236 GFlops, terwijl Broadwell E met 440 GFlops aan kop gaat. Kaby Lake haalt 282 GFlops en Excavator schommelt rond de 64 GFlops.
Conclusie
Ryzen houdt goed stand bij CPU2006 en Stream. De veel duurdere Broadwell-E springt er alleen uit als hij zijn vier geheugenkanalen echt kan benutten. Bij singlethread-gebruik scoort hij vaak lager, zelfs bij het voor AVX-geoptimaliseerde SPECfp. Intels compiler uit de Composer-suite 2017 levert doorgaans snellere code op Intel- en AMD-systemen dan die van Microsoft Visual Studio 2017. Als je de problematische benchmark 462.libquantum echter weglaat, is het verschil nog maar zo’n 10 tot 20 procent. Soms delven de Intel-compilers echter ook het onderspit, zoals bij sommige metingen van de Flops-benchmark.
Tip

Download het e-book en krijg direct inzicht in de stappen die jouw organisatie moet zetten.



Praat mee