



Er klinkt een leuk nummer uit de luidsprekers in het café, maar niemand van je vrienden kan op de titel komen. Aan de tafel naast je wordt luidkeels over voetbal gediscussieerd, maar het lukt Shazam toch om het nummer te herkennen aan de hand van een korte opname die je met je smartphone maakt. Hoe werkt Shazam eigenlijk?
Lees verder na de advertentie
Audio-fingerprinting werd voor het eerst in 2003 gepresenteerd in een whitepaper van Avery Li-Chun Wang (pdf-versie), een van de oprichters van Shazam. Daarin presenteert hij een algoritme voor het identificeren van muzieknummers op basis van korte opnames die je met een mobiele telefoon maakt.
Mobiele telefoons uit het jaar 2000 waren daadwerkelijk niet meer dan dat: je kon ze meenemen en ermee bellen, maar de uitgebreide functies van smartphones waren nog ver weg. De kwaliteit van de microfoon, het verwerken van signalen door het apparaat en de GSM-signaalkwaliteit waren maar enkele van de technische obstakels die destijds nog onoverwinbaar leken. Chris Barton, een van de oprichters en voormalig CEO van Shazam, weet daar vermakelijk over te vertellen in een video.
Ondanks alle scepsis hield Shazam stug vast aan het verwezenlijken van zijn visie en nam Li-Chun Wang in dienst. Ook hij achtte het in eerste instantie nog onmogelijk, maar hij ontwikkelde een bijzonder slim algoritme waarmee hij een jaar later het probleem al had opgelost. In 2001 verliep dat nog via een telefoongesprek, tegenwoordig gaat het met een app.
Tip

Download het e-book en krijg direct inzicht in de stappen die jouw organisatie moet zetten.
Het principe achter Shazam
Het principe achter het algoritme is eenvoudig: het bepaalt wat de karakteristieke audio-eigenschappen van een fragment (probe) zijn – de vingerafdruk – en zoekt naar overeenkomsten in een database van audio-vingerafdrukken van originele nummers. Shazam heeft daarbij niet alle aspecten van audio-fingerprinting zelf uitgevonden, maar heeft wel het probleem wel weten op te lossen om opnames te herkennen waarin veel achtergrondruis zit en die met een beperkte gegevensoverdracht worden verzonden.
Shazam heeft de details van zijn algoritme nooit volledig openbaar gemaakt. Aan de hand van het principe hebben enkele hobbyontwikkelaars echter hun eigen varianten van het algoritme geïmplementeerd, aan de hand waarvan je goed kunt afleiden hoe het origineel van Shazam zo ongeveer moet werken.
Een eenvoudig principe
De muziekdatabase van Shazam ordent de audiovingerafdrukken die verkregen zijn uit korte opnames toe aan de metadata van nummers, waaronder de titel, de artiest en het album. Er moet echter gezocht worden met een korte opname van het nummer vol met ruis en bijgeluiden.

Opsporen
Een muzieknummer kun je beschrijven als een opeenvolging van tonen, waarbij een toon wordt gedefinieerd door zijn hoogte (frequentie) en sterkte (amplitude). Aan de hand daarvan probeert Shazam de muziek te herkennen. Daarbij negeert het overige toonparameters zoals de duur en klankkleur. Om de muziekdatabase succesvol te kunnen raadplegen, heeft Shazam een audio-vingerafdruk nodig die het nummer eenduidig identificeert. Dat werkt in principe via een serie paren (tupels), die bestaan uit de frequentie (toonhoogte) en het geluidsvolume (toonsterkte). Op welk moment die te horen zijn (toonvolgorde), maakt elk nummer uniek identificeerbaar.
Een audiosignaal wordt als een serie van duizenden samples op een smartphone of pc opgeslagen. Die vormen een registratie van de luchtdruk respectievelijk de mate van trilling van het microfoonmembraan in intervallen van 0,02 ms. De frequenties kun je daar echter niet direct uit aflezen. Voor het bepalen van de frequenties wordt een Fouriertransformatie gebruikt, die een audiosignaal afbeeldt als frequenties en amplitudes binnen een bepaald tijdsbestek. Voor digitale audiosignalen wordt een discrete Fouriertransformatie gebruikt, die efficiënt kan worden berekend.
Ook bij de snelle versie, de Fast Fourier Transform (FFT), is de frequentieanalyse nog altijd een rekenintensief proces. Het is daarom zaak om de hoeveelheid data die moet worden berekend zo beperkt mogelijk te houden. Bij een digitaal audiosignaal kan dat onder meer door stereokanalen naar mono te downmixen (indien de smartphone meer dan één kanaal opneemt), en door het zogenaamde ‘downsampling’, oftewel het samenvoegen van opeenvolgende samples. Hoe Shazam dat exact doet, houdt het bedrijf geheim. In het whitepaper wordt gemeld dat met audiobestanden worden gewerkt met 8 kHz 16-bit mono-samples.
Het resultaat van de Fouriertransformatie is een spectrogram van een nummer met driedimensionale informatie over toonhoogte, toonsterkte en tijd. Dat kan worden weergegeven als een tweedimensionale heatmap, waarbij tijd de x-as is, toonhoogte de y-as en verschillende kleuren het geluidsvolume representeren. Blauwe pixels zijn de zachte tonen en rode pixels de harde.
De hoeveelheid data is echter veel te groot om daarmee een query naar een database te sturen. Shazam filtert daarom alleen de bijzonder luide tonen (peaks) eruit en let daarbij alleen op een zo gelijkmatig mogelijke verdeling van die peaks gedurende het verloop van het muziekstuk. Shazam meldt verder niet welke definitie zij voor luide tonen hanteren. De community op internet is het echter met elkaar eens dat er rekening wordt gehouden met de eigenschappen van het menselijke gehoor, waarbij lage tonen als zachter en hoge tonen als luider worden ervaren. De muziekindustrie weet dat ook en versterkt de lage tonen in een mix. Om de meest significante tonen te bepalen, moet er daarom een frequentieafhankelijk drempelfilter zijn. Dat houdt bovendien rekening met de eigenschap van veel muziekstukken dat die aan het begin en aan het eind zachter klinken dan in het midden.
Van muziekstuk tot vingerafdruk
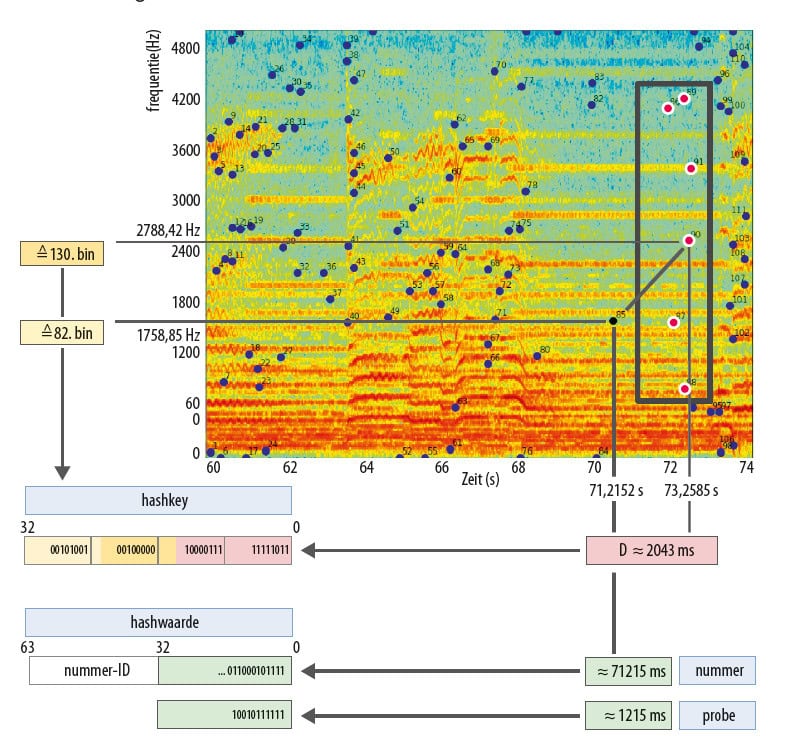
Shazam zoekt het spectrogram af naar piekparen, waaruit hashkeys van 32 bit worden berekend. Uit alle in de constellation map gevonden hashkeys stelt het een audiovingerafdruk samen.
Wil je meer interessante achtergrondinformatie en gratis tips? Schrijf je in voor de nieuwsbrief:
Sporen veiligstellen
Als je de pieken in een apart diagram zet, lijkt dat een beetje op een sterrenkaart. Daarom omschrijft het whitepaper dat ook wel als ‘constellation map’. Zo’n constellation map representeert de meest significante tonen van een nummer gelijkmatig verdeeld over tijd. Als je het algoritme op een kort fragment toepast, berekent hij daar ook een constellation map voor.
Desondanks is het geen goed idee om voor één probe de constellation maps van miljoenen nummers af te zoeken op zoek naar een match. Uitgaande van 30 pieken per seconde zou de zoekopdracht van een probe van 10 seconden in een database van 1 miljoen nummers van gemiddeld 3 minuten zo’n 1,5 biljoen operaties vergen (30 × 10 × 30 × 10 × 1.000.000 × 3 × 60) – en dat zonder rekening te houden met mogelijke fouten in de probe.
Het oplossen van het probleem van een efficiënte zoektocht is feitelijk de clou achter het algoritme. De basis is het idee om in plaats van naar aparte pieken meteen naar meerdere pieken in één keer te zoeken. Dat doet Shazam door een constellation map in zogenaamde ’target zones’ in te delen en voor elke zone een piek als ankerpunt te bepalen. Vervolgens combineert Shazam de frequentie van elke piek binnen een target zone met de frequentie van het toegewezen ankerpunt en het tijdsverschil tussen beide pieken. Het resultaat is een bitreeks (hashkey) die Shazam samen met de tijdpositie van het ankerpunt in een database opslaat. De hashkeys en timemarkers van een constellation map vormen dan samen de audiovingerafdruk van het nummer of van de probe.
- Maakt AI de kwantumcomputer overbodig?
- Gaten in veiligheid messengers
- Docker-containers automatisch updaten
- Verschillen in front-ends

Doelzones
Shazam beschrijft helaas niet volgens welke methode target zones gedefinieerd worden. Nagemaakte implementaties op internet pakken bijvoorbeeld om het n-aantal pieken één piek samen met een m-aantal pieken die op die eerste piek volgen, en gebruiken daarvoor waarden van 1 tot 5 voor n en 5 tot 7 voor m.
De hashkeys bestaan uit 32 bits: 9 bits voor de beide pieken en 14 bits voor hun tijdsverschil. Daarmee kun je 512 (29) verschillende frequenties onderscheiden, die bij een samplerate van 1 milliseconde maximaal rond 16 seconden (214/1000) afstand mogen hebben. Bij muziekstukken als ASAP van John Cage zal dat niet werken, maar voor populaire muziek werkt dat prima.
Een constellation map met 30 pieken per seconde en target zones met 5 pieken heeft voor een vingerafdruk van een nummer van 3 minuten een resultaat van 27.000 waarden (30 × 5 × 3 × 60) bij maximale overlap van de target zones (als je elke piek ook nog eens als ankerpunt kiest). Als je bijvoorbeeld alleen elke derde piek als ankerpunt vastlegt, reduceert dat het totaal tot 9000 waarden. Als je dat vermenigvuldigd met een realistisch aantal van 50 miljoen nummers in een muziekdatabase voor audiovingerafdrukken, is het resultaat ook voor die kleinere waarde nog steeds 450 miljard hashkeys. Daar moeten ook nog redundanties tussen zitten, omdat je met 32-bit hashkeys maximaal ongeveer 4 miljard waarden kunt onderscheiden. Dezelfde hashkey kan ook daadwerkelijk in meerdere nummers voorkomen. De key wordt in dat geval meerdere keren in de database opgenomen, telkens gekoppeld aan een nummer-ID en de positie van de hashkey in het nummer.
De koppeling tussen timemarkers en nummers wordt gemaakt in het lijstelement als combinatie van beide waarden met telkens 32 bit, waarbij de waarde voor het nummer een ID is. Door het op die manier te organiseren, wordt de vingerafdruktabel in de muziekdatabase begrensd tot maximaal 232, zodat het mogelijk is die met de hashkey te indexeren.
Databasevergelijking
Het zoeken verloopt vervolgens in stappen. Allereerst stuurt het algoritme een query naar de database met alle hashkeys van de probe – in feite diens vingerafdruk. Het resultaat voor elke hashkey is een lijst van nummers en timemarkers waar die hashkey voorkomt. Het algoritme beschikt dan over een lijst van alle nummers in de database die een overeenkomst bevatten.
Of het gezochte nummer ook in de database staat, hangt ervan af of er een nummer tussen zit met timemarkers in de hashkey die dezelfde relatieve afstand hebben als die in de probe. Een dergelijke overeenstemming vind je eenvoudig in een diagram dat de verdeling van de timemarkers weergeeft als een strooiveld van punten, waarvan de coördinaten zich bevinden op de tijdsposities van zowel de probe als het muziekstuk. Een treffer herken je aan een significante ophoping van punten in de vorm van een diagonaal lopende lijn.
Voor een mathematische oplossing van dat probleem worden meestal regressie-methoden gebruikt. Dit vergt echter intensieve berekeningen. Shazam gebruikt daarom een andere aanpak: de corresponderende timemarkers van de probe en het nummer in het diagram kunnen geformuleerd worden als tm = tp + Δtp, waarbij tm de timemarker van het nummer en tp die van de probe is. Daarbij duidt Δtp het verschil aan tussen beide timemarkers. Die kan worden berekend met Δtp = tm – tp. Het algoritme berekent die verschillen voor elk spreidingsvelddiagram, dus alle nummers van de zoekresultaten, en maakt daar telkens een histogram van. De laatste stap onderzoekt de histogrammen dan op afwijkingen. Als één ervan een statistisch significante afwijking van het gemiddelde van alle resultaten heeft, dan is de kans groot dat dit het gezochte nummer is. Dat komt doordat de tijdverschillen bij het juiste nummer veel minder zullen verschillen dan bij de andere nummers, die alleen door toeval enkele overeenkomstige hashkeys hebben.
Efficiënte database
De audiovingerafdrukken vormen de basis van de muziekdatabase. Voor elke hashkey is er een lijst van nummer-ID’s met timemarkers waarop de hashkey betrekking heeft. Om met een probe in de muziekdatabase te gaan zoeken, stelt Shazam allereerst een audiovingerafdruk samen van die probe. De datastructuur verschilt echter iets van die van een muzieknummer en bestaat uit een lijst van de hashkeys die uit de probe zijn gewonnen en hun tijdsposities.

Voor de performance van de beschreven procedure zijn twee factoren bepalend: de hoeveelheid berekeningen die nodig zijn voor het zoeken in de vingerafdruktabel van de muziekdatabase en de berekeningen die nodig zijn voor het analyseren van de lijst met treffers. Bij het zoeken met de hashkeys van een probe gaat het om een veldindex. De vingerafdruktabel kan door zijn compacte formaat voor een groot aantal nummers in het werkgeheugen zitten (in-memory). De audiovingerafdrukken van 50 miljoen nummers met 9000 waarden per nummer en 64 bit per waarde nemen bijvoorbeeld ongeveer 4 TB in beslag (50.000.000 × 9000 × 64/8). Als het werk over meerdere servers wordt verdeeld, levert dat geen problemen op.
De moeite die voor het zoeken gedaan moet worden, hangt af van de duur van de probe. Hoe langer die is, hoe meer bijbehorende hashkeys er zijn. Elke hashkey vergt echter maar één tabeltoegang. Bij de analyse is het van belang om de hoeveelheid data van de kandidaten zo klein mogelijk te houden. Omdat de hashkeys zeer specifiek zijn, zal het aantal potentiële kandidaten te overzien zijn.
Het procedé van Shazam werkt buitengewoon goed, zoals je snel merkt als je de app gebruikt. Ook de vrij beschikbare implementaties op internet laten zien hoe effectief het principe werkt. Het algoritme is snel en vindt het nummer met grote betrouwbaarheid, mits het in de database is opgenomen natuurlijk.
Ten slotte nog een persoonlijke anekdote: Shazam was in staat om bij een optreden de live-versie van een nummer te identificeren. De muzikanten konden het nummer dus op de milliseconde nauwkeurig exact naspelen, of het was in feite helemaal niet live.
(Jürgen Schuck, c’t magazine)
- Maakt AI de kwantumcomputer overbodig?
- Gaten in veiligheid messengers
- Docker-containers automatisch updaten
- Verschillen in front-ends
Tip

Krijg direct toegang tot alle beschikbare edities op je laptop, tablet of smartphone.



Een vraag, kan ik shazammen én telefoneren te gelijk?
Het algoritme van Shazam kan ruis en bijgeluiden uitfilteren, als je tijdens het bellen even niet praat zou het moeten lukken (5-10 seconden). Deel je ervaringen hier zodat anderen er iets aan hebben!
ik heb een vraag…is het mogelijk om de Shazam bibliotheek over te zetten naar mijn pc