


De oeroude werkwijze om crawlers, zoekmachine-robots en andere automatische bezoekers met een robots.txt te vertellen welke webpagina’s ze mogen bezoeken, werkt nog steeds. Bindend is die informatie echter niet, waardoor je ongewenste bezoekers op een andere manier moet buitensluiten.
Lees verder na de advertentie
Een omstreden aankondiging bracht de oude techniek weer voor het voetlicht: “Robots.txt werkt niet goed met webarchieven”, kondigde de blog van het Internet Archive in april aan. De digitale archivarissen willen in de toekomst geen rekening meer houden met de zoekmachinespecifieke instellingen van een website. Daarmee sluiten ze zich aan bij het minder bekende Archive Team, die zich hierover minder diplomatiek uitlaten: “Robots.txt is a stupid, silly idea.”
Het Robot Exclusion Protocol, de officiële naam van de techniek, vertelt zoekmachines welke url’s ze wel en niet mogen meenemen. Dat moet vooral servers ontlasten. Volgens sommige statistieken zijn bots verantwoordelijk voor meer dan de helft van alle traffic. Bovendien moeten de robots-aanwijzingen voorkomen dat zoekmachines verouderde informatie weergeven. Daarnaast worden websitebeheerders gestraft voor dubbel aanwezige (‘duplicate’) content en belandt bepaalde content niet bij Google – bijvoorbeeld foto’s of pdf’s.
Tip!

Slimme IP-camera’s met live toezicht en haarscherpe beveiliging!

De robots-aanwijzingen zijn echter niet meer dan een vriendelijk verzoek, geen toegangsbeperking. De crawlers van de grote zoekmachines houden zich er aan, maar andere niet. Met name boosaardige bots die op zoek zijn naar zwakke plekken of gevoelige content, zullen de aanwijzingen negeren. Ze zullen de mappen dan juist eerder bijzonder grondig doorploegen.
Google wijst er nadrukkelijk op dat robots.txt geen geschikt middel is om een pagina betrouwbaar uit de Google-index te houden. Crawlers houden bij een directe link vanaf een andere website blijkbaar geen rekening met de aanwijzingen. Als je op je webserver iets te verbergen hebt of diensten wilt afschermen, moet je andere maatregelen treffen. Je kunt toegang bijvoorbeeld blokkeren met .htaccess. Informatie die niemand mag zien, heeft op het vrij toegankelijke internet niets te zoeken. Ook voor het probleem van duplicate content is er met canonieke url’s een alternatieve oplossing.
Horen de robots-aanwijzingen dan tot de overbodige ballast of op de dumpplek van oude technieken? Niet als je naar de grote namen kijkt: websites als google.com, microsoft.com, twitter.com en apple.com hebben op hun servers allemaal omvangrijke robots-bestanden staan. Blijkbaar gebruiken zij robots.txt als SEO-tool.
Robottechniek
De specificatie van robots.txt is al meer dan 20 jaar oud. Het concept is simpel: crawlers zoeken in de hoofddirectory van een webserver eerst naar een bestand met de naam robots.txt. Daarna gaan ze een website pas doorspitten. Op die manier zullen de bots gevoelige url’s niet bezoeken. Het bestand geldt voor alle bestanden en submappen met hetzelfde protocol (HTTP of HTTPS), dezelfde domeinnaam (inclusief subdomeinen) en hetzelfde poortnummer. Het ziet er ongeveer zo uit:
# commentaar
User-agent: Bot1
User-agent: Bot2
Disallow: /
User-agent: *
Allow: /fotos/ik.jpg
Disallow: /fotos/ # commentaar
Crawl-delay: 10
De items beginnen met een of meerdere User-agent-regels en worden gescheiden door lege regels. De naam na User-agent geldt voor de botnaam. Grote of kleine letters maken daarbij niet uit. Voor Disallow en Allow zijn absolute of relatieve paden toegestaan. Complete url’s zijn verboden. Het eerste codeblok verbiedt de genoemde bots toegang tot alle content op de website. Het tweede blok geldt voor andere bots en verbiedt toegang tot de map ‘fotos’ – met uitzondering van het daar opgeslagen bestand ik.jpg.
De Allow-regel is al een uitbreiding van de standaard – net als Crawl-delay. Daarmee vraagt robots.txt of het indexeren van het volgende bestand het opgegeven aantal seconden kan wachten om de serverbelasting te verlagen. Bing, Yahoo en Yandex respecteren dat, de Google-bot niet. Sommige bots begrijpen ook zoekpatronen bij paden, bijvoorbeeld *.gif, .bak$ en /tmp*/.
Sitemaps
Tenslotte is robots.txt ook de plek waar je met Sitemap:
[pad]
naar een sitemap verwijst. Sitemaps zijn opsommingen van url’s in leesbaar of XML-formaat. Ze geven aan welke pagina’s door zoekmachines geïndexeerd kunnen worden en met welke frequentie en prioriteit ze bijgewerkt zouden moeten worden.
Ondanks de simpele syntaxis van robots.txt sluipen er al snel fouten in:
User-agent: *
Disallow: /private/
User-agent: Googlebot
Disallow: /test/
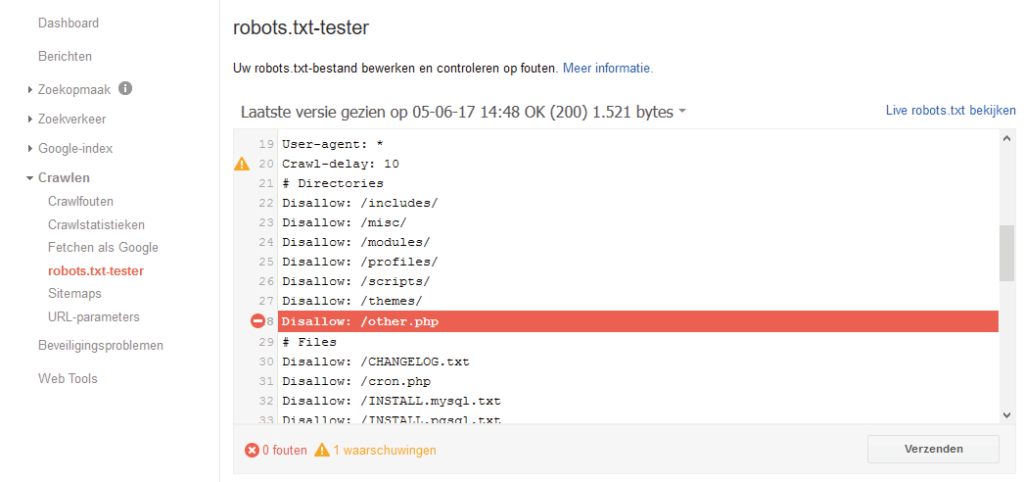
Vermoedelijk zul je verwachten dat de Google-bot de map private met rust laat. Het tegendeel is echter waar. Omdat het robots.txt-bestand hem expliciet noemt, hoeft hij zich alleen aan de Disallow-regel bij zijn naam te houden. Om de Google-bot dan opdracht te geven de map private te negeren, moet je de bovenstaande Disallow-regel kopiëren of het complete Google-botblok verwijderen. Vergeet dan ook niet om je robots.txt te testen.
Het bestand robots.txt is een krachtige tool. Fouten kunnen dus fataal zijn. Een Disallow: / is genoeg om je website naar niemandsland te verbannen. De praktijk om embedded resources als scripts, stijlen en high-res foto’s uit de indexering te laten is problematisch: de zoekmachine-bots willen een webpagina net zo zien als een mens en straffen dergelijke trucs dan ook af.
Decentraal
Als uitbreiding of alternatief voor centrale robots-bestanden kun je je wensen op het niveau van webpagina’s declareren. Dat kan in de vorm van <meta>-tags of als HTTP-header X-Robots-Tag. Anders dan bij robots.txt kun je er daarbij van uitgaan dat ‘goede’ bots die aanwijzingen in elk geval volgen. Bovendien kun je er meer mee differentiëren:
<meta name=”robots”
content=”noindex, nofollow”>
Dat komt overeen met een Disallow in robots. txt: bots moeten de pagina niet indexeren en de links niet volgen. Voor een deel hebben bots nog meer aanwijzingen nodig, die met robots.txt niet mogelijk zijn. Bijvoorbeeld noarchive (niet in de zoekmachinecache opslaan) en nosnippet (geen beschrijvende tekst of preview). De Google-bots kennen nog een interessante feature:
<meta name=”googlebot”
content=”unavailable_after:
Thursday, 01-Jun-17 12:00:00 CEST”>
Deze pagina moet op 1 juni 2017 uit de Google-index zijn verdwenen. De datumopmaak komt overeen met de minder gebruikelijke standaard RFC 850.
De waarde robots in het name-attribuut is te vervangen door de naam van een specifieke bot. De voor content toegestane waarden kun je ook met de X-Robots-Tag in de HTTP-header instellen. Om een bepaalde bot te adresseren, schrijf je de waarde in de vorm botname: noindex.
Meer bots
De bot-namen die je voor robots.txt nodig hebt, zijn niet hetzelfde als hun User-agent-string. ‘Goede’ bots sturen echter hun naam en een documentatie-url mee, bijvoorbeeld Googlebot/2.1; http://www.google.com/bot.html. Google heeft ook andere bots, waarbij met name Googlebot-Image relevant is. Let op: niet alles wat zich Googlebot noemt is er ook een – dat is alleen te controleren aan de hand van het ip-adres en/of de remote host.
De andere grote zoekmachines sturen Bingbot, Yandexbot, Sluro (Yahoo) of Baiduspider op datajacht. Daarnaast zijn er verschillende bots van SEO- en marketingspecialisten, die zich een beeld vormen van backlinks, branding en vacatures – bijvoorbeeld de backlinks- zoekmachine OpenLinkProfiler en de Amazon-dochter Alexa, die rangvolgordes voor websites opstelt. Hun crawler ‘ia_archiver’ wordt vaak verward met die van Archive.org, maar die heet archive.org_bot.
Bot-portier
Voor robots die niet naar vriendelijke woorden willen luisteren, kun je een uitsmijter implementeren. Met een .htaccess-bestand in de root van de webserver is dat ook zonder toegang tot de serverconfiguratie te bewerkstelligen:
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT}
(bot1|bot2)
[NC]
RewriteRule ^ - [L,R=403]
Bots die zich met een bepaalde User-agent-string identificeren, krijgen op alle pagina’s de error 403 Forbidden. Bij de ergste bezoekers, die hun ware identiteit verbergen, helpt alleen het buitensluiten op basis van het ip-adres:
RewriteCond %{REMOTE_ADDR}
145.133.160.212
Je kunt het juiste adres in de logbestanden van je server vinden. Helaas kan een ip-adres-blokkade ook onschuldigen treffen, zeker in tijden van cloudhosting. Kijk uit met mod-rewrite. Het is namelijk een wonderbaarlijke tool om je webpresence grondig te ruïneren. Na elke aanpassing moet je dus grondig testen.
Daarbij is mod-rewrite wel het juiste middel om de Archive-bot buiten te sluiten. Je kunt reeds gearchiveerde webpagina’s laten verwijderen door een mail te sturen naar [email protected]. Een kleine troost: alleen bij vaak bezochte websites slaat het Archive meer op dan alleen de startpagina.
door Herbert Braun / Noud van Kruysbergen / Marcel van der Meer
Tip

Download het e-book en krijg direct inzicht in de stappen die jouw organisatie moet zetten.



Praat mee