



Veel taalmodellen zeggen dat ze opensource zijn, maar doen daarbij alsof. Als je digitale soevereiniteit nastreeft of aan strenge wettelijke eisen moet voldoen, moet je nauwkeuriger kijken. We geven een overzicht van licenties en modellen.
Lees verder na de advertentie
Wanneer is een AI-model echt open source?
Digitale soevereiniteit, gevoelige bedrijfs- of gezondheidsgegevens, strenge transparantie-eisen of rechtszekerheid: er zijn veel redenen om generatieve (taal)modellen lokaal te gebruiken of op zoek te gaan naar een zo onafhankelijk mogelijke oplossing.
Het gebruik van opensourcesoftware belooft een maximale creatieve vrijheid en veel controle, vooral omdat die beter voldoet aan de eisen van de bestaande Europese verordening van AI dan de eigen systemen van OpenAI, Google en aanverwanten.
In de AI-wereld hebben veel spelers echter hun eigen interpretatie van opensource, waarschijnlijk om het begrip in hun voordeel te verwateren. Het meest prominente voorbeeld is Meta, dat zijn taalmodel Llama onverstoorbaar aanprijst als opensource, hoewel het maar aan een paar criteria voldoet.
We schetsen hier de belangrijkste eisen en kijken welke modellen daar überhaupt aan voldoen.
Wat klassieke opensourcesoftware, van officeprogramma’s tot besturingssystemen, kenmerkt, is duidelijk gedefinieerd door het Open Source Initiative, dat op zijn website precies aangeeft welke licenties aan die eisen voldoen (zie de link op het einde).
Tot de criteria behoren onder andere: vrije verspreiding, open broncode, afgeleide werken zijn toegestaan, geen discriminatie van personen en gebruiksdoeleinden.
Bij machine-learning-systemen en met name bij generatieve modellen kunnen onderzoekers en ontwikkelaars echter weinig met de broncode alleen, omdat die alleen de structuren en mechanismen definieert waarmee de neuronen en lagen met elkaar communiceren. Om de werking van moderne AI net zo transparant en beïnvloedbaar te maken als klassieke software, moeten ook alle belangrijke parameters en componenten van een trainings-pipeline openbaar gemaakt worden – van de trainingsgegevens en -gewichten tot de checkpoints en de afstemming en finetuning.
Tip

Download nu en lees alles over de specifieke eisen voor CAD-toepassingen en toekomstbestendige workstations.

Gekaapte definitie
Een pionier op het gebied van openheid was de 176-parameter LLM Bloom, ontwikkeld door een collectief van onderzoekers onder leiding van Hugging Face, maar die was vanwege zijn enorme omvang moeilijk te hanteren. De doorbraak in de community kwam uiteindelijk met Llama van Meta. In tegenstelling tot wat Meta beweert, is dat echter geen opensource-model, maar een openweights-model, waarbij alleen de trainingsparameters (gewichten) gedocumenteerd zijn.
Bovendien zijn de licentievoorwaarden van de daarvoor geldende Llama 3.1 Community License in strijd met de eisen voor opensource, onder andere omdat ze het commerciële gebruik beperken, zoals de Open Source Initiative (OSI) regelmatig bekritiseert.

Iets soortgelijks vind je bij veel licentievoorwaarden, bijvoorbeeld in de Qwen License waaronder Alibaba de grotere varianten van zijn Qwen – zoals Qwen2.5-72B – publiceert. Alleen de meeste kleinere Qwen-varianten vallen onder de supertoegankelijke Apache 2.0-licentie.
Vergelijkbaar daarmee is de MIT-licentie, die ook onbeperkt gebruik voor privé- en commerciële doeleinden, wijziging en verspreiding van de LLM toestaat, zolang de copyrightvermelding behouden blijft. Die geldt bijvoorbeeld voor DeepSeek V3, maar met enkele beperkingen, bijvoorbeeld voor militair gebruik – wat in strijd is met de eisen van het OSI.
Als je onaangename verrassingen wilt voorkomen, moet je dus van tevoren controleren of het beoogde gebruik überhaupt verenigbaar is met de kleine lettertjes.
De Free Software Foundation (FSF) heeft op haar website een overzicht van conforme en niet-conforme licenties samengesteld.
Data is de helft van de code
Commerciële ontwikkelaars beperken het gebruik van hun modellen echter niet alleen met licentievoorwaarden, maar ook door essentiële informatie achter te houden, waardoor zelfstandig verder ontwikkelen of onafhankelijk onderzoek belemmerd wordt. Llama is meestal gratis en kan lokaal geïnstalleerd worden, maar Meta heeft vanaf het begin alleen de initialisatiecode en de trainingsgewichten gepubliceerd.
Tot de categorie Open Weights Model behoren onder andere ook DeepSeek R1, Qwen, Gemma, Kimi K2, GPT-OSS van OpenAI en de Phi-serie van Microsoft. Meta, Microsoft, Google, OpenAI, Anthropic en dergelijke documenteren het trainingsproces en de checkpoints evenmin als de trainingsgegevens – of in het beste geval gedeeltelijk.
Dat heeft enerzijds auteursrechtelijke redenen. De meeste generatieve AI’s zijn getraind met materiaal dat op internet gepubliceerd is, zoals krantenartikelen, songteksten, enzovoort. Juristen over de hele wereld discussiëren en onderhandelen nog steeds over de rechtmatigheid van die aanpak.
Maar het gaat vooral om concurrentievoordelen. De trainingsgegevens vormen en verfijnen samen met de trainingsstrategie in een proces met meerdere fases van pretraining, posttraining en afstemming het algoritme dat uiteindelijk de tekst (of afbeeldingen, video’s enzovoort) genereert. Daarin ligt een groot deel van het bedrijfsgeheim van de eigen modellen en minder in de ruwe broncode of in de gewichten.
De OSI en de FSF verwijten Meta met name dat het de term opensource in zijn eigen voordeel herdefinieert: “In een tijd waarin Meta opensource probeert te herdefiniëren in zijn eigen voordeel en ten koste van onze vrijheid, roepen we de hele opensourcegemeenschap op om zich te verenigen en Meta’s open-washing aan de kaak te stellen.”
Om dat tegen te gaan, heeft de OSI vorig jaar een eigen opensourcedefinitie voor artificiële intelligentie ontwikkeld, de OSAID, om onduidelijkheden weg te nemen en de interpretatiebevoegdheid te behouden:
– Gebruik is voor alle doeleinden mogelijk, zonder toestemming te hoeven vragen;
– Het systeem is te bestuderen, evenals de componenten en de werking ervan;
– Aanpassen mag voor elk doel, inclusief wijzigingen in de output;
– Delen van het systeem met anderen is toegestaan, gewijzigd of ongewijzigd.
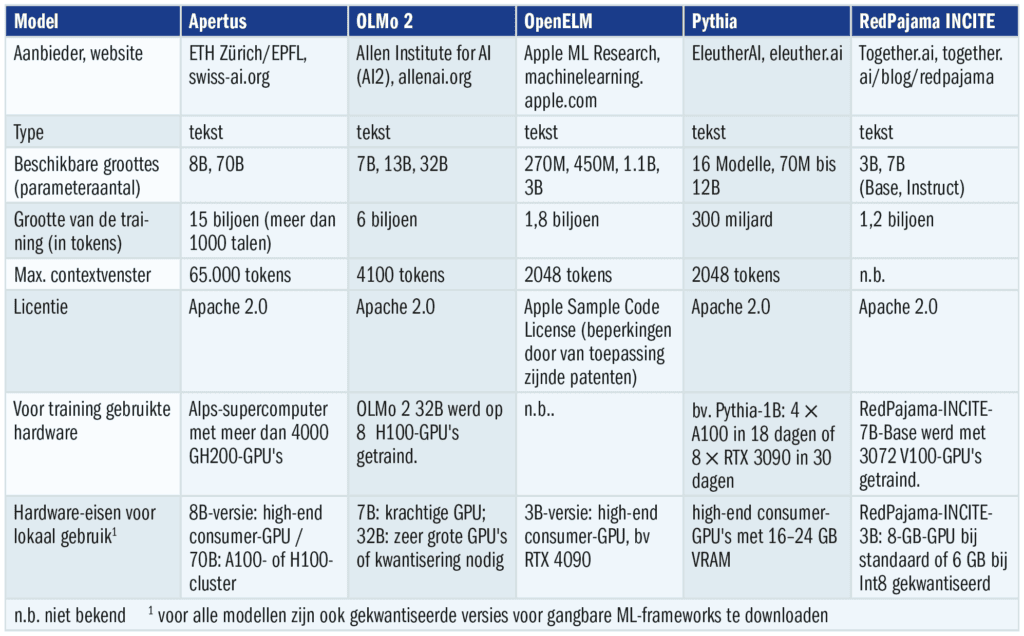
De Nederlandse onderzoekers Andreas Liesenfeld en Mark Dingemanse hebben in 2024 een interessant onderzoek over dit onderwerp geschreven en een gedifferentieerde maatstaf ontwikkeld waarmee de openheid van de systemen kan worden vergeleken.
Transparantie met zeldzame waarde
Uiteindelijk blijven er een handvol noemenswaardige grote taalmodellen over die onbeperkt kunnen worden gebruikt zoals het Open Source Initiative eist – en zoals dat bij klassieke OSS het geval is door het simpelweg publiceren van de broncode. Het ene heet OLMo en wordt in de VS ontwikkeld door het Allen Institute for AI (AI2). Achter dat non-profit onderzoeksinstituut zit een goed gefinancierde stichting van Microsoft-oprichter Paul Allen.
Het tweede heet Apertus, bestaat in een versie met 8 en 70 miljard parameters en is afkomstig van een Zwitsers onderzoekerscollectief van de ETH Zürich en de EPFL Lausanne. Het is meertalig getraind en wordt gefinancierd met belastinggeld en investeringen. De enorme rekenkracht wordt geleverd door de eigen Alps-supercomputer in Lugano.
Een bijzonderheid is dat de Zwitserse onderzoekers een filtertechniek hebben ontwikkeld om auteursrechtelijk kritisch materiaal achteraf uit het trainingscorpus te verwijderen.
Dat dit zinvol is, blijkt uit het geval van OpenELM van Apple. Het bedrijf wordt nu geconfronteerd met een rechtszaak omdat het zijn opensourcemodel, dat is geoptimaliseerd voor gebruik op kleine apparaten, had getraind met de RedPajama-database, die op zijn beurt e-books uit illegale bronnen bevatte.
Iets ouder zijn het in 2023 gepubliceerde 12-miljard-parameters-model Pythia van EleutherAI en het daarop gebaseerde Dolly 2.0 van Databricks. Meer dan 5000 medewerkers van Databricks hebben meegewerkt aan de arbeidsintensieve opbouw van een eigen Instruction Tuning-dataset.
Waarom dat nodig was, legt het team uit in zijn blog: de gegevens die werden gebruikt voor het trainen van versie 1.0, die het Alpaca-ontwikkelingsteam van Stanford University automatisch had gemaakt met behulp van de OpenAI-API, zouden licentieproblemen hebben opgeleverd.
De gebruiksvoorwaarden verbieden namelijk het trainen van modellen die concurreren met OpenAI. Daardoor mogen potentiële gebruikers de eerste Dolly-versie waarschijnlijk niet commercieel gebruiken – een serieuze beperking waar ook Alpaca, Koala, GPT4All en Vicuna mee te maken hebben.
Ook het Together.ai-team heeft voor zijn 3B-/7B-modelreeks RedPajama-INCITE een eigen database opgezet, die is gebaseerd op die van Llama. Er is echter een vermoeden dat deze database beschermde werken bevat die afkomstig zijn uit illegale bronnen – concreet gaat het om de Books3-collectie die is samengesteld door AI-onderzoeker Shawn Presser, maar die inmiddels niet meer toegankelijk is. Technisch gezien is het instructiemodel gebaseerd op GPT-NeoX van Eleuther-AI.
Conclusie
Het opensource AI-landschap is versnipperd en ondoorzichtig, commerciële spelers strijden met non-profit-initiatieven om de interpretatieve macht. Het is belangrijk dat de term niet verwatert en dat open-washing voorkomen wordt, zoals uit ons overzicht blijkt.
De meeste taalgeneratoren die als opensource worden aangeprezen, blijken bij nader inzien open-weights-modellen te zijn. Die hebben zeker hun nut, omdat ze eenvoudig lokaal kunnen worden geïnstalleerd en in gebruik genomen en voor de meeste doeleinden gratis zijn. Toch gaat het om propriëtaire software.
Echte opensource AI streeft er daarentegen naar bedrijven en wetenschappers volledige transparantie en onbeperkt gebruik te garanderen – van aanpassingen van de modelarchitectuur en training met eigen gegevens tot afstemming en finetuning.
Het aantal mensen dat fundamenteel onderzoek kan doen is wel beperkt – wie heeft er nou een supercomputer? Maar vooral grotere bedrijven die streven naar een zo hoog mogelijk niveau van rechtszekerheid, gegevensbescherming en transparantie, of daartoe verplicht zijn, kunnen dergelijke modellen met relatief weinig moeite optimaliseren (finetunen) met hun eigen gegevens.
De meest consequente weg is ingeslagen door het Amerikaanse non-profit onderzoeksinstituut Allen AI met OLMo en de Zwitserse onderzoekers met Apertus: beiden hebben hun gegevensverzamelingen zorgvuldig samengesteld en proberen beschermd materiaal eruit te filteren. Bovendien zijn hun LLM’s zowel in kleine als in middelgrote omvang beschikbaar, waardoor ze ook geschikt zijn voor veeleisendere taken.
Het verschil met een ChatGPT of Gemini lijkt in eerste instantie groot, op dit moment lopen ze ongeveer twee tot drie jaar achter op de grensverleggende modellen.
Met meer steun en financiële middelen zouden ze het verschil echter kunnen verkleinen en dan niet alleen ten goede komen aan geprivatiseerde bedrijven, maar aan het algemeen belang.
Andrea Trinkwalder en Noud van Kruysbergen
Tip

Krijg direct toegang tot alle beschikbare edities op je laptop, tablet of smartphone.



Praat mee