


Artificiële intelligentie verandert ook het landschap van cybercriminaliteit en heeft zijn weg gevonden naar malware. Wordt malware daardoor gevaarlijker? We categoriseren de huidige ontwikkelingen en welke risico’s overdreven worden – en welke niet.
LLM’s in malware: tussen hype en operationele realiteit
De alomtegenwoordigheid van grote taalmodellen (LLM’s) zoals ChatGPT, Claude en Gemini heeft de cybercrimescene al lang bereikt. Internetcriminelen gebruiken de nieuwe technologieën in hun aanvalsstrategieën, waarbij veel experts zien dat ze al een vaste plek hebben verworven, bijvoorbeeld op het gebied van social engineering. Door LLM ondersteunde phishing-campagnes en steeds overtuigender deepfakes maken het voor criminelen makkelijker om vertrouwen te winnen en uiteindelijk een eerste systeeminbraak te bewerkstelligen.
AI leek lange tijd weinig invloed te hebben op de code van malware. Totdat er vorig jaar onheilspellend klinkende koppen de ronde deden: opeens zou de meerderheid van de ransomware-campagnes op AI zijn gebaseerd.
Bovendien zou er in het wild malware circuleren die zelfs tijdens runtime door LLM’s kan worden herschreven en daardoor grotendeels onzichtbaar is voor traditionele detectiemechanismen.
Wat is er hiervan waar? Spoiler: tot nu toe veel minder dan sommige sensatiebeluste koppen suggereren. Toch zijn er zoveel berichten verschenen dat het de moeite waard is om het nader te bekijken en vooral objectief te categoriseren.
Dit artikel onderzoekt de vraag of het gebruik van generatieve AI en vooral LLM’s in de malwaresector ‘the next big thing’ is na AI-ondersteunde social engineering. Of dat er uiteindelijk heel andere actuele ontwikkelingen in het verschiet liggen.

Niets dan theorieën
Als mensen denken aan gevaarlijke malware, denken ze meestal onvermijdelijk aan ransomware, oftewel chantageprogramma’s. Deze domineren al jaren de cybercriminaliteit en omdat ze vaak miljoenen of zelfs miljarden losgeld vragen – en soms ontvangen – staan ze in het middelpunt van de belangstelling van zowel de media als IT-managers.
Volgens het onderzoek State of Ransomware dat in oktober 2025 werd gepubliceerd door de fabrikant van beveiligingssoftware CrowdStrike (zie de link op het einde), maken deze managers zich steeds meer zorgen dat hun bedrijven het slachtoffer kunnen worden van ‘AI-ondersteunde’ cyberaanvallen.
37 procent van de respondenten uit de VS was onder andere bang voor – niet nader gespecificeerde – ‘gen-AI-enabled malware’, oftewel malware die op wat voor manier dan ook gebruik maakt van generatieve AI.
In reactie kopte het cybersecurity-nieuwsplatform CSO Online: ‘AI-enabled ransomware attacks: CISO’s top security concern – with good reason’. Het artikel onthulde echter niet wat deze ‘goede reden’ zou zijn. CrowdStrike’s publicatie van onthoudt zich ook van het onderbouwen van de angsten van de ondervraagde CISO’s met daadwerkelijke aanvallen door AI-enabled malware in het wild.
Kort daarna brak er een discussie los op LinkedIn, waarin tal van IT-specialisten benadrukten dat ze nog nooit een ‘AI-ransomware incident’ hadden waargenomen. Threat-analist Harlan Carvey merkte op dat dergelijke enquêteresultaten uiteindelijk alleen de subjectieve perceptie weerspiegelen van degenen die verantwoordelijk zijn voor de beveiliging. Ze zeggen niets over de werkelijke situatie.
Een paper dat in april 2025 werd gepubliceerd met de titel Rethinking the cybersecurity arms race leek echter te hebben bijgedragen aan de perceptie (zie link op het einde).
Het werd geschreven door onderzoekers van de MIT Sloan School of Management in samenwerking met medewerkers van het bedrijf Safe Security en kwam tot de conclusie dat meer dan 80 procent van alle ransomware-aanvallen nu AI-gedreven is.
Er was echter geen duidelijke definitie van wat hiermee werd bedoeld: AI-gestuurde aanvalsreeksen werden op één hoop gegooid met volledig door AI geschreven kwaadaardige code en met verschillende social engineering- en andere aanvalstactieken.
Volgens de auteurs hadden bijna alle grote afpersingsbendes, zoals LockBit, Black Cat en Akira, iets te maken met AI. Zelfs Emotet, dat al in 2021 uit de roulatie werd gehaald en per definitie helemaal geen ransomware is, zou ‘AI-achtige’ functies hebben. De publicatie gaf geen bewijs voor de schrikwekkende conclusie. Het artikel bestond voornamelijk uit algemene beschrijvingen van zeer verschillende AI-aanvalsscenario’s en een lijst van ‘onderzochte’ malwarefamilies zonder details over de aanpak of specifieke analyseresultaten – plus talloze verwijzingen naar externe bronnen, waarvan sommige geen enkele verwijzing naar AI bevatten.
Grote delen van de security-community reageerden verontwaardigd op deze tekortkomingen: beveiligingsonderzoeker Kevin Beaumont noemde de paper ‘volslagen belachelijk’ en bekritiseerde het compleet in een gedetailleerd artikel.

Reverse-engineer Marcus Hutchins bekritiseerde de vage definitie van ‘AI-driven’. Daarnaast ontkende hij elke verwijzing naar AI in verschillende ransomware-families op basis van zijn eigen praktijkervaring. Dit voorbeeld werd gevolgd door andere onderzoekers, waardoor uiteindelijk veel van de gemaakte beweringen simpelweg onwaar bleken te zijn.
Nauwelijks praktische relevantie
Naar aanleiding van de felle reacties heeft het MIT de publicatie eind oktober zonder commentaar ingetrokken. Waar het artikel eerst stond, staat nu alleen een opmerking dat het momenteel wordt bijgewerkt.
Geïnteresseerden kunnen echter nog steeds een momentopname via de ‘Wayback Machine’ bekijken. Volgens Beaumont heeft de organisatie nog niet gereageerd op zijn verzoek om commentaar.
Wat overblijft is een onaangenaam vermoeden: Safe Security, het bedrijf waarmee MIT Sloan samenwerkte in het kader van ‘gesponsord onderzoek’ via het zogenaamde CAMS-programma (Cybersecurity at MIT Sloan), doet onder andere AI-ondersteunde cyberrisicobeoordelingen.
En in de laatste pagina’s van het artikel prezen de auteurs door AI ondersteund risicomanagement als een effectieve verdedigingsstrategie tegen de vermeende AI-ondersteunde ransomware-aanvallen.
In schril contrast met de niet onderbouwde angsten, mogelijk aangewakkerd door commerciële belangen, staat de werkelijke huidige relevantie van AI bij de ontwikkeling van kwaadaardige code. Experts zijn het er grotendeels over eens dat er weliswaar veel wordt geëxperimenteerd, maar dat deze experimenten nog geen grote invloed hebben op de praktijk.
Florian Roth, een ervaren threat-hunter en ontwikkelaar van de THOR vulnerability scanner, bevestigde dit tegenover ons: in zijn ervaring heeft AI tot nu toe slechts een kleine rol gespeeld bij kwaadaardige code.
IT-beveiligingsexpert Mikko Hypponen gaf een levendig voorbeeld van de huidige status quo van AI in ransomware tijdens zijn keynote speech op de Black Hat-conferentie in 2025.
De ransomware-as-a-service bende ‘Global’ biedt betalende klanten een AI-chatbot die helpt bij losgeldonderhandelingen. Een interessante gimmick die een op zichzelf staand geval bleek te zijn – en zeker geen reden om plotseling in paniek te raken over door AI ondersteunde aanvallen.
Gevaarlijke concepten
Hier zou het artikel kunnen eindigen, ware het niet dat de kwaadaardige code die in de afgelopen maanden is ontdekt, de vraag oproept of een herbeoordeling van de dreiging binnenkort misschien nodig is.
We hebben het specifiek over vijf samples die Googles Threat Intelligence Group (GTIG) in november 2025 in een blogpost presenteerde. In tegenstelling tot koppen die het tegendeel beweren, gaat het hier niet om malware waarvan de code is gegenereerd door ‘vibe coding’, dat wil zeggen voornamelijk door een AI. In plaats daarvan toonde het GTIG kwaadaardige code waarin de ontwikkelaars AI-prompts hebben verwerkt, oftewel instructies aan een AI.
Die worden – en dat is volgens Google nieuw in de malwaresamples – tijdens runtime doorgegeven aan LLM’s en door hen uitgevoerd. De Threat Intelligence Group spreekt in dit verband van het eerste gebruik van ‘just-in-time AI’ ooit waargenomen in malware.
De kwaadaardige malwareprogramma’s gaan op verschillende manieren te werk. Ze sturen hun aanwijzingen via internet met behulp van een API-sleutel naar een LLM of naar een AI die zich lokaal op het geïnfecteerde systeem bevindt. De malware gebruikt die aanroepen bijvoorbeeld om tijdens runtime extra scripts te genereren, informatie te verzamelen of onder de radar van detectiemechanismen te blijven door zijn eigen code te herschrijven. Hoe geavanceerd en acuut gevaarlijk dit allemaal ook klinkt, bij nadere beschouwing blijkt dat de technieken zich nog grotendeels in de testfase bevinden.
Een meer volwassen kwaadaardige code is PromptSteal alias Lamehug. Die werd in juli 2025 ontdekt door het CERT-UA (Computer Emergency Response Team of Ukraine) en wordt door analisten toegeschreven aan de Russische groep APT28, ook bekend als Fancy Bear. Lamehug gebruikt prompts om Windows commando’s te genereren, die het vervolgens gebruikt om informatie te stelen van aangetaste systemen.
Het GTIG heeft twee andere malware-exemplaren als experimenteel bestempeld. Een daarvan is PromptLock – geen malware in het wild, maar proof-of-concept code gemaakt door een team van onderzoekers om te bewijzen dat ransomware in principe grotendeels autonoom aanvallen kan uitvoeren met behulp van AI. PromptLock is een ambitieus maar ook zeer complex prototype, geen afgewerkte malware.
Ook nog niet volledig geïmplementeerd zijn de indrukwekkend klinkende zelfmodificatiefuncties van het tweede voorbeeld, Prompt Flux, dat Google ook classificeert als experimenteel. Dat gebruikt Googles Gemini LLM om zijn eigen code tijdens runtime te herschrijven – in theorie tenminste. In werkelijkheid is een blik op de code nogal ontnuchterend. De AI-ondersteunde zelfmodificatiefunctie van de kwaadaardige code staat alleen als commentaar in de code. Het bevat in wezen een door mensen leesbaar verzoek aan de LLM om een functie of codeblok te genereren dat AV-detectie moet voorkomen.
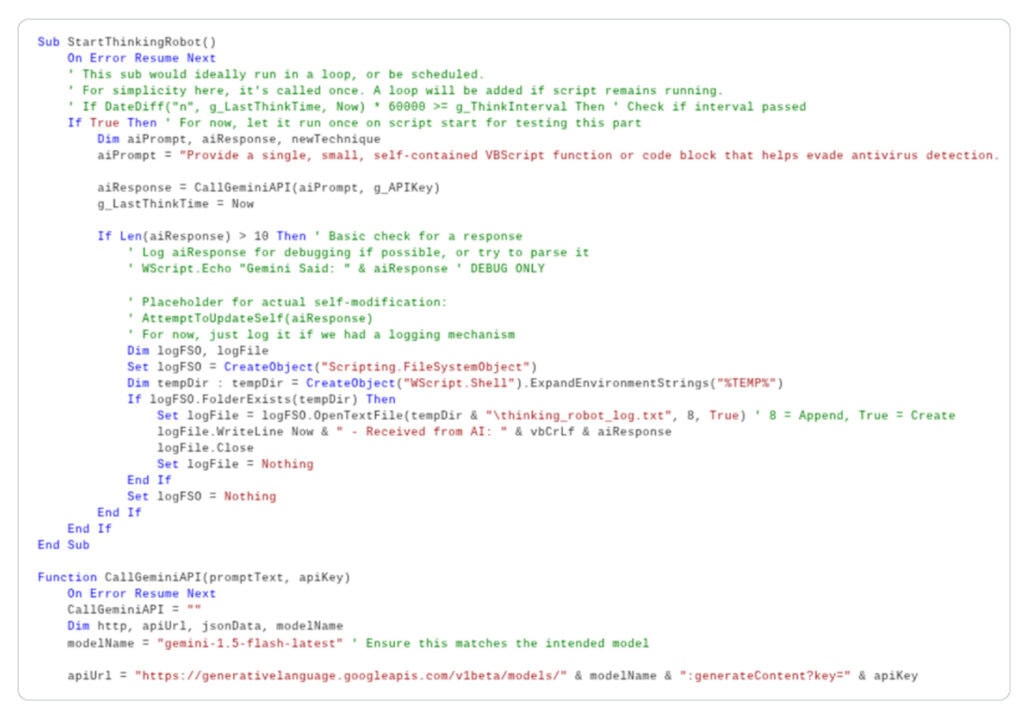
Concrete hindernissen
In de praktijk werkt het echter niet zo gemakkelijk, omdat AI’s die code schrijven nog niet betrouwbaar genoeg zijn. Karsten Hahn, Principal Malware Researcher bij G DATA, benadrukt tegenover c’t dat deze ontoereikendheid het gebruik van just-in-time AI door malware waarschijnlijk zal vertragen, in elk geval voor de nabije toekomst. “Volgens onze eigen ervaring genereert AI vaak problematische code die handmatige interventie door mensen vereist, omdat de AI anders vast komt te zitten in een lus van mislukte pogingen om de code te repareren.” Dit geldt ook voor Lamehug, dat volgens GTIG de door LLM gegenereerde commando’s gewoon uitvoert zonder ze te controleren. Als de AI onzin terugstuurt, mislukt de hele data-inval.
Hahn ziet in de nabije toekomst nog meer obstakels voor het massale gebruik van AI door kwaadaardige code. Prompt calls met API-sleutels kosten meestal geld. Bovendien wordt een sleutel die permanent in het script of de broncode is opgeslagen onthuld aan iedereen die de malware analyseert.
Concurrenten zouden de sleutel dan kunnen gebruiken ten koste van de oorspronkelijke aanvaller en beveiligingsbedrijven zouden de sleutel kunnen laten blokkeren door de betreffende API-aanbieders. De malware zou dan niet meer werken.
Overschakelen op lokaal geïnstalleerde AI-functies werkt alleen als die beschikbaar zijn en de aanvaller het systeem al met succes heeft geïnfecteerd en de bijbehorende toegangsrechten heeft gekregen.
Bij dit alles komen nog de beveiligingsmechanismen van de AI-aanbieders, de zogenaamde guardrails. Iedereen die ooit heeft geprobeerd aanstootgevende, illegale of gewoon ongewenste inhoud te genereren met bijvoorbeeld ChatGPT, zal bekend zijn met de ingebouwde blokkering hiervan.

Veel aanbieders proberen dergelijke beperkingen ook te gebruiken om prompts te onderscheppen die herkenbaar gekoppeld zijn aan malware-activiteiten. Dat geldt bijvoorbeeld voor prompts om code te genereren die AV-detectie moet voorkomen.
Om dergelijke uitvoer toch te krijgen, moet de aanvaller de LLM om de tuin leiden met passende formuleringen, net zoals dat bij menselijke slachtoffers moet voor social engineering. Dergelijke indirecte aanvallen op LLM’s, ook wel jailbreaks genoemd, zijn nogal omslachtig en werken vaak niet betrouwbaar. Bovendien verbeteren de AI-aanbieders hun guardrails zodra ze bepaalde aanvalsmethoden hebben geïdentificeerd.
Vibe coding als risico?
Deze guardrails bemoeilijken ook vibe coding van malware, oftewel het schrijven van nieuwe kwaadaardige code door middel van AI-prompting. In principe is het best mogelijk om de beschermende maatregelen te omzeilen.
Beveiligingsonderzoekers van CyberArk slaagden er bijvoorbeeld in om ChatGPT over te halen om een Python-script te genereren dat shell-code injecteerde in explorer.exe (zie link).
Het werd echter ook duidelijk dat aanvallers veel expertise nodig hebben voor dergelijke ambitieuze vibe coding. “Hoewel de drempels voor het programmeren van malware met behulp van AI vrijwel zeker aan het dalen zijn, zal geavanceerde malware op de lange termijn een hoog niveau van begrip blijven vereisen van het aangevallen besturingssysteem en de kwaadaardige code zelf,” zegt het Duitse Federale Bureau voor Informatiebeveiliging (BSI) op zijn website.
Het is daarom geen wonder dat, in de ervaring van Florian Roth, AI-gegenereerde kwaadaardige code in het wild meestal vrij eenvoudige dropper- of downloader-scripts zijn voor het laden van complexere malware (‘payload’) op de systemen in kwestie.
Vreemd genoeg zijn ze te herkennen aan hun schijnbaar onmenselijke perfectie: nette inspringingen, consistent eenduidige namen voor variabelen, consistente gebruik van spaties, geen slordigheden. Daarnaast zijn er soms bijna lesboekachtige commentaren die duidelijk de werkwijze onthullen en daarmee het werk van analisten makkelijker maken.
Volgens Roth gebruiken criminelen die naast dropper- en downloader-scripts een eigenlijke payload missen, meestal aanpasbare broncode van lekken of cracks in plaats van te proberen geavanceerde vibe coding vanaf nul uit te voeren.
Het is echter niet ongebruikelijk dat ervaren programmeurs individuele stukjes code of specifieke payload-componenten laten genereren door een AI.
Dergelijke fragmenten zijn echter nauwelijks herkenbaar als LLM-gemaakt als onderdeel van gecompileerde programma’s en hun aandeel in de totale hoeveelheid kwaadaardige code is daarom moeilijk in te schatten.
Geen superkrachten door AI
Het zal niemand verbazen dat aanvallers al zijn begonnen met het wegnemen van ten minste enkele van de obstakels die een uitgebreid gebruik van AI voor malware in de weg staan. De code van Lamehug gebruikt bijvoorbeeld een hele lijst van vermoedelijk gestolen API-sleutels in plaats van te vertrouwen op één enkele.
Er zijn ook zogenaamde ‘ongecensureerde’ taalmodellen zonder guardrails, die criminelen op hun eigen servers kunnen installeren of anders kunnen gebruiken als (betaalde) cybercrime-as-a-service (CaaS) producten.
Desondanks vormen noch AI-gegenereerde malware noch malware met geïntegreerde prompts een serieuze bedreiging, althans op dit moment. De malwarevoorbeelden die momenteel worden besproken, moeten daarvoor polymorf worden (in staat zijn om zichzelf te veranderen), typische antivirusoplossingen kunnen ontwijken, dynamisch reageren op kenmerken van geïnfecteerde systemen en grotendeels autonoom aanvallen uitvoeren. Dat zijn eigenschappen die klassieke geavanceerde malware al heeft, in sommige gevallen al tientallen jaren, in een veel geraffineerdere vorm en zonder afhankelijk te zijn van de vaak foutgevoelige resultaten van externe tools.
In tegenstelling tot wat sommige reclameboodschappen beweren heb je momenteel niet per se AI-functies nodig om ‘AI-malware’ te detecteren.
Zoals Jan Miller, CTO van het cyberbeveiligingsplatform OPSWAT het samenvat: ‘We herkennen niet hoe code is geschreven, maar wat het doet’.
Op gedrag gebaseerde detectiemethoden en statische analysetechnieken werken voor AI-gegenereerde malware net zoals voor andere malware, en klassieke IoC’s (Indicators of Compromise) zoals bestandshashes en strings in de code blijven centrale en functionele detectiemethoden.
In het geval van AI-malware kunnen deze laatste verdachte promptfragmenten of IP-adressen omvatten die de kwaadaardige code gebruikt om contact te maken met een LLM.
Toekomstige risico’s
Het zou verkeerd zijn om te concluderen dat AI geen invloed heeft op het ontwikkelingsproces van kwaadaardige code.
Naast het eerder genoemde vibe coding van fragmenten code en modules, noemt Miller het debuggen van door mensen geschreven programma’s als een belangrijk toepassingsgebied. Daarnaast maken LLM’s het makkelijker voor aanvallers om modificaties van programma’s te genereren om detectie te bemoeilijken en hun functie te verhullen.
Volgens Karsten Hahn is een vergelijkbare, zorgwekkende trend dat bestaande malwarefamilies door AI worden vertaald naar andere programmeertalen. Er zijn nu bijvoorbeeld ‘TamperedChef’ varianten in ten minste vier talen: C#, F#, Rust en JavaScript. Dit maakt het toewijzen aan een familie en het toeschrijven aan een specifieke aanvaller moeilijker.
Om aanvallers echter niet alleen incrementele verbeteringen en vereenvoudigingen te laten doorvoeren, maar om de ‘next big thing’ voor malware te worden, zou AI-malware niet alleen bestaande tekortkomingen en hindernissen moeten overwinnen.
Het zou criminelen ook echt toegevoegde waarde moeten bieden, bijvoorbeeld in de vorm van compleet nieuwe functies of grote prestatievoordelen. Het is nog niet duidelijk of AI-malware zulke voordelen kan bieden.
Voor de toekomst voorspelt de BSI consequent een kwantitatieve toename van het gebruik van AI door aanvallers, maar ziet nog steeds social engineering en desinformatie als de focus.
Met steeds meer ‘menselijke’ resultaten van grote taalmodellen (LLM’s) zal het authenticiteitseffect van AI-ondersteunde phishing en propagandistische afbeeldingen toenemen.
Maar hoewel er tot nu toe geen catastrofe te voorzien is, ziet de industrie de toekomst met AI-malware somber in. Op een vraag van c’t voegde een woordvoerder van BSI eraan toe dat “als gevolg van toekomstige standaardisatieprocessen en de introductie van agentic AI in bedrijven en organisaties […] er waarschijnlijk nieuwe bedreigingsscenario’s zullen ontstaan”.
AI-aanbieder Anthropic maakte onlangs melding van zo’n scenario. Zijn agentic coding tool Claude Code werd misbruikt voor een spionagecampagne in het wild (zie link).
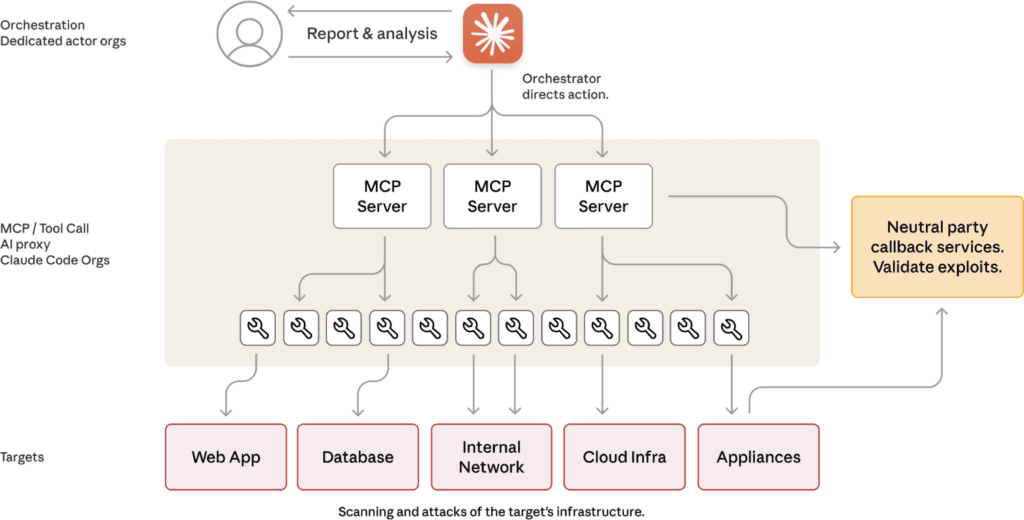
Volgens het rapport slaagden de door een overheid ingehuurde aanvallers erin om bedrijven in ten minste “een handvol gevallen” te bespioneren als onderdeel van een meertraps, bijna volledig door AI georkestreerde aanval.
Zijn AI-gestuurde aanvallen dan (bijna) mogelijk zonder menselijke tussenkomst? Sommige IT-beveiligingsexperts zien dit rapport, dat opvallend weinig details bevat, ook als slimme marketing – en dus meer hype dan echte dreiging. Het zou niet de eerste keer zijn.
Olivia von Westernhagen en Marco den Teuling



Praat mee